Simple kunstige neurale netværk til multipel klassifikation
Et kunstigt neuralt netværk fungerer på den måde, at man på baggrund af en række forskellige informationer gerne vil kunne forudsige en eller anden ting. Det kan være, at man på baggrund af en række forskellige blodprøveværdier vil forudsige, om en patient har en bestemt sygdom. Det kunne også være, at man baseret på svarene fra en række forskellige spørgsgmål vil udtale sig om, om en person vil stemme på rød eller blå blok. De nævnte eksempler kalder man for binær klassifikation – fordi der i hvert tilfælde er to muligheder: syg/ikke syg og rød blok/blå blok. Men det er ikke svært at forestille sig scenarier, hvor der kan være mere end to klasser. For eksempel er eksemplet med rød og blå nok tvivlsomt. Her ville det måske være bedre at prøve at forudsige et bestemt parti. Denne note handler om, hvordan man udvider en simpel kunstig neuron, så den ikke kun kan bruges til binær klassifikation, men derimod til at forudsige hvilke blandt flere klasser et givent tilfælde befinder sig i. Lad os starte med et eksempel.
Hvor hårdt skal du arbejde i matematiktimerne?
Du kender det sikkert godt. Der er gruppearbejde i matematiktimen, og du gider egentlig ikke. Det er nemmere bare at snige sin mobiltelefon i lommen og drible i kantinen. På den anden side er du også ambitiøs og vil gerne have en god karakter til eksamen. Din lærer er også frustreret. Hun vil gerne være over de elever, som ellers ville stikke af, så de får lært noget sjovt matematik. What to do? Svaret er selvfølgelig, at vi skal have udviklet en AI assistent til din lærer, så hun får hjælp til at hjælpe jer!

Lad os sige at du svarer på følgende tre spørgsmål på en skala fra 1 til 10:
\(x_1\): Hvor godt har jeg sovet i nat? (1="Elendigt", 10="Fantastisk").
\(x_2\): Hvor spændende er det emne, vi er i gang med lige nu? (1="Mega kedeligt", 10="Det er awesome").
\(x_3\): Hvor godt vil jeg gerne klare mig til eksamen? (1="Jeg er ligeglad", 10="Det skal gå så godt som muligt").
Baseret på disse tre spørgsmål er der nu følgende fire valg, du kan træffe (eller som din lærer måske bare i stilhed observerer):
- Jeg bliver i klassen, hvor læreren kan hjælpe mig, og regner alt det, jeg kan.
- Jeg sætter mig ud og regner opgaverne, så godt jeg kan.
- Jeg går i kantinen og sniger min telefon med – jeg prøver at regne nogle få opgaver.
- Jeg går hjem (og håber på ikke at få fravær)!
Det valg du træffer, skal vi have oversat til matematik (beklager, men nu er det jo en matematik tekst, du er i gang med at læse!). Det gør vi ved at definere fire forskellige værdier \(t_1, t_2, t_3, t_4\).
Hvis du vælger 1. sætter vi: \[ t_1 = 1, \quad t_2=0, \quad t_3=0, \quad t_4=0. \]
Hvis du vælger 2. sætter vi: \[ t_1 = 0, \quad t_2=1, \quad t_3=0, \quad t_4=0. \]
Hvis du vælger 3. sætter vi: \[ t_1 = 0, \quad t_2=0, \quad t_3=1, \quad t_4=0. \]
Hvis du vælger 4. sætter vi: \[ t_1 = 0, \quad t_2=0, \quad t_3=0, \quad t_4=1. \]
Det kan man repræsentere lidt smart ved hjælp af en vektor i fire dimensioner:
\[ \vec{t}= \begin{pmatrix} t_1 \\ t_2 \\ t_3 \\ t_4 \\ \end{pmatrix} \]
Vektoren \(\vec t\) kaldes for targetværdien eller targetvektoren.
Læg mærke til, at der altid gælder følgende
\[ t_1 + t_2 + t_3 + t_4 = 1. \tag{1}\]
Da netop én af koordinaterne i \(\vec t\) er \(1\), mens resten er \(0\), kalder man også \(\vec{t}\) for en one hot vektor. Det får vi brug for senere.
Træningsdata
Vi forestiller os nu, at vi har stillet 12 elever de tre spørgsmål ovenfor. Derefter har vi observeret hvilket af de fire valg, de træffer. Det kunne se sådan her ud:
| Elev nr. | \(x_1\) (søvn) | \(x_2\) (emne) | \(x_3\) (eksamen) | Valg |
|---|---|---|---|---|
| \(1\) | \(10\) | \(10\) | \(10\) | \({\color{#020873} 1}\) |
| \(2\) | \(8\) | \(7\) | \(8\) | \({\color{#020873} 1}\) |
| \(3\) | \(9\) | \(6\) | \(10\) | \({\color{#020873} 1}\) |
| \(4\) | \(4\) | \(10\) | \(10\) | \({\color{#020873} 1}\) |
| \(5\) | \(5\) | \(8\) | \(7\) | \({\color{#8086F2} 2}\) |
| \(6\) | \(10\) | \(7\) | \(4\) | \({\color{#8086F2} 2}\) |
| \(7\) | \(7\) | \(7\) | \(10\) | \({\color{#8086F2} 2}\) |
| \(8\) | \(8\) | \(3\) | \(4\) | \({\color{#F2B33D} 3}\) |
| \(9\) | \(6\) | \(2\) | \(5\) | \({\color{#F2B33D} 3}\) |
| \(10\) | \(10\) | \(2\) | \(2\) | \({\color{#F2B33D} 3}\) |
| \(11\) | \(1\) | \(1\) | \(3\) | \({\color{#F288B9} 4}\) |
| \(12\) | \(5\) | \(2\) | \(2\) | \({\color{#F288B9} 4}\) |
For eksempel har elev nummer 1 sovet fantastisk, eleven synes, at emnet er vildt spændende, og eleven vil gerne klare sig rigtig godt til eksamen – denne elev vælger derfor at blive i klassen. Targetværdien for denne elev er:
\[ \vec{t}= \begin{pmatrix} 1 \\ 0 \\ 0 \\ 0 \\ \end{pmatrix} \]
Eleven nummer 12 har derimod sovet semi godt, til gengæld synes eleven ikke at emnet er særlig spændende, og er også ligeglad med at klare sig godt til eksamen. Denne elev laver derfor en "sniger" og går hjem. Targetværdien for eleven er derfor:
\[ \vec{t}= \begin{pmatrix} 0 \\ 0 \\ 0 \\ 1 \\ \end{pmatrix} \]
Data i tabel 1 kaldes for træningsdata.
I figur 1 er træningsdata indtegnet i et tre-dimensionelt koordinatsystem. Punkterne har koordinatsæt \((x_1, x_2, x_3)\) og punktets farve angiver valget (mørkeblå svarer til 1, lyseblå svarer til 2, gul svarer til 3 og lyserød svarer til 4).
Det, vi gerne vil nu, er at lave et meget simpelt kunstigt neuralt netværk, som vi fremover kan bruge til at forudsige, hvilket valg du skal træffe baseret på svaret på de tre spørgsmål. Så idéen er altså, at du i et fremtidsscenarie svarer på de tre spørgsmål, og så fortæller din nye AI assistent dig, hvilket valg du skal træffe. Det er da smart – eller måske lidt dumt, men nu er det jo også bare et eksempel!
Lad os forklare, hvordan man kan gøre det – blot i et lidt mere generelt tilfælde.
Feedforward
Vi forestiller os, at vi generelt har \(n\) inputvariable
\[ x_1, x_2, \dots, x_n. \]
I eksemplet ovenfor var \(n=3\), fordi vi svarede på tre spørgsmål.
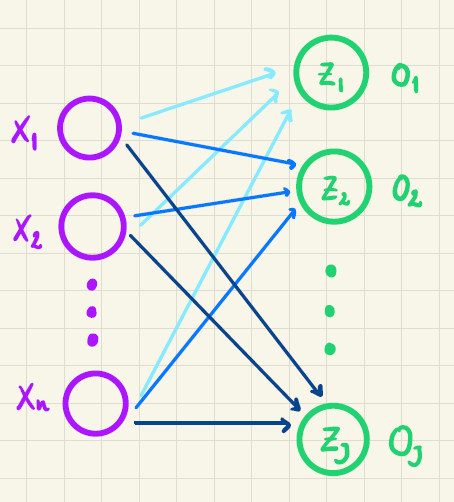
Disse \(n\) inputvariable er vist i figur 2 som lilla cirkler. De grønne cirkler repræsenterer \(J\) output neuroner (i vores eksempel er \(J=4\), fordi der skal træffes et valg blandt 4 muligheder).
Vi ønsker at træne netværket, så \(o_1\) bliver sandsynligheden for at et givent træningseksempel tilhører klasse \(1\), \(o_2\) skal være sandsynligheden for at træningseksemplet tilhører klasse \(2\) og så videre. Hvis man vil skrive det lidt kompakt op, kan man samle alle outputværdierne i en vektor:
\[ \vec{o} = \begin{pmatrix} o_1 \\ o_2 \\ \vdots \\ o_J \end{pmatrix} \]
I vores eksempel vil det svare til, at \(o_1\) skal være sandsynligheden for, at du bliver i klassen og regner opgaver (mulighed 1), \(o_2\) skal være sandsynligheden for, at du sætter dig ud og regner opgaver og så videre.
Det vil sige, at det skal være sådan, at
\[ o_1 + o_2 + \cdots + o_J = 1 \tag{2}\]
fordi sandsynlighederne for de \(J\) forskellige muligheder til sammen skal give 1.
Vi vil starte med at se på, hvordan vi på baggrund af inputvariablene \(x_1, x_2, \cdots, x_n\) kan beregne de \(J\) outputværdier, så ovenstående er opfyldt. På figur 2 illustrerer de forskelligt farvede pile, at alle \(n\) inputvariable sendes frem i netværket til alle \(J\) outputværdier. Så for eksempel sendes \(x_1, x_2, \cdots, x_n\) frem til \(o_1\) (vist ved de lyseblå pile), ligesom de også sendes frem til \(o_2\) (vist ved de mellemblå pile) og så videre.
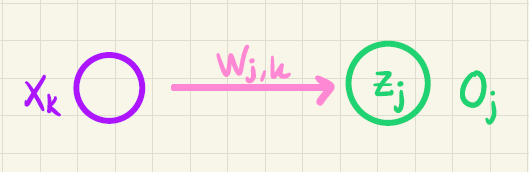
For at forklare den beregning der så foregår, har vi i figur 3 kun vist de pile, som går fra inputvariablene frem til den \(j\)’te outputværdi.
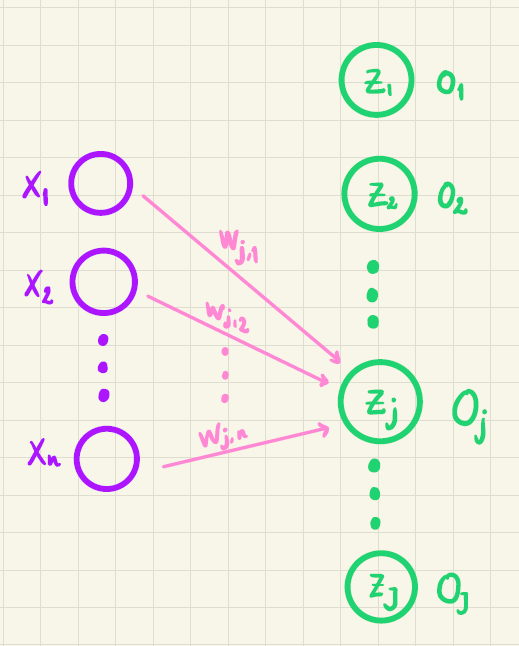
Før \(o_j\) bestemmes, beregner vi først en værdi \(z_j\) på denne måde:
\[ z_j = w_{j,0} + w_{j,1} \cdot x_1 + w_{j,2} \cdot x_2 + \cdots + w_{j,n} \cdot x_n. \]
Tallene \(w_{j,0}, w_{j,1}, w_{j,2}, \cdots, w_{j,n}\) kaldes for vægte.
Værdien \(z_j\) er vist i figur 3 inde i den grønne cirkel. På tilsvarende vis beregnes \(z_1, z_2, \cdots, z_J\). Bemærk her, at vægtene er forskellige. For eksempel er
\[ z_2 = w_{2,0} + w_{2,1} \cdot x_1 + w_{2,2} \cdot x_2 + \cdots + w_{2,n} \cdot x_n \]
så vægtene er her \(w_{2,0}, w_{2,1}, w_{2,2}, \cdots, w_{2,n}\).
I alt er der \((n+1)\cdot J\) forskellige vægte (det vil sige i vores eksempel vil der være \((3+1)\cdot4=16\) vægte).
Alle \(z\)-værdierne kan antage et hvilket som helst reelt tal og kan alene af den grund ikke fortolkes som en sandsynlighed. Vi bruger derfor en såkaldt aktiveringsfunktion \(\alpha\) på alle \(z\)-værdierne, så vi kan få beregnet en outputværdi, som kan fortolkes som en sandsynlighed:
\[ o_j = \alpha(z_1, z_2, \dots, z_J), \]
hvor
\[ 0 \leq \alpha(z_1, z_2, \dots, z_J) \leq 1. \]
Som aktiveringsfunktion \(\alpha\) vil vi bruge en funktion, som kaldes for softmax, fordi den præcis har de egenskaber, som vi efterspørger – det ser vi lige om lidt. På baggrund af alle \(z\)-værdierne beregnes \(o_j\) ved hjælp af softmax på denne måde:
\[ o_j = \alpha(z_1, z_2, \dots, z_J) = \frac{\mathrm{e}^{z_j}}{\sum_{i=1}^J \mathrm{e}^{z_i}}. \tag{3}\]
For det første kan vi se, at både tæller og nævner er positive. Derfor må \(o_j>0\). For det andet er \(\mathrm{e}^{z_j} < \sum_{i=1}^J \mathrm{e}^{z_i}\) og derfor er
\[ o_j = \frac{\mathrm{e}^{z_j}}{\sum_{i=1}^J \mathrm{e}^{z_i}} < \frac{\sum_{i=1}^J \mathrm{e}^{z_i}}{\sum_{i=1}^J \mathrm{e}^{z_i}} = 1. \]
Altså er
\[ 0<o_j<1 \]
hvilket betyder, at \(o_j\) kan opfattes som en sandsynlighed. Endelig er
\[ \begin{aligned} o_1 + o_2 + \cdots + o_J &= \frac{\mathrm{e}^{z_1}}{\sum_{i=1}^J \mathrm{e}^{z_i}} + \frac{\mathrm{e}^{z_2}}{\sum_{i=1}^J \mathrm{e}^{z_i}} + \cdots + \frac{\mathrm{e}^{z_J}}{\sum_{i=1}^J \mathrm{e}^{z_i}} \\ &= \frac{\mathrm{e}^{z_1} + \mathrm{e}^{z_2} + \cdots + \mathrm{e}^{z_J}}{\sum_{i=1}^J \mathrm{e}^{z_i}} \\ &= \frac{\sum_{i=1}^J \mathrm{e}^{z_i}}{\sum_{i=1}^J \mathrm{e}^{z_i}} = 1, \end{aligned} \]
hvilket også var det krav, vi stillede til de beregnede outputværdier i (2).
I det helt specielle tilfælde, hvor der kun er to output neuroner, vil softmax-funktionen for \(o_1\) blot være en funktion af to variable:
\[ o_1 = \frac{\mathrm{e}^{z_1}}{\mathrm{e}^{z_1} + \mathrm{e}^{z_2}} \]
Grafen for denne funktion er vist i figur 4. Her ses det tydeligt, at værdien af \(o_1\) ligger i intervallet \(]0,1[\).
Det betyder, at hvis \(o\)-værdierne beregnes som defineret i (3), er der altså tale om en sandsynlighedsfordeling. Beregningen af alle \(z\)- og \(o\)-værdier kan udføres, hvis bare man kender alle vægtene. I et neuralt netværk kaldes disse udregninger for feedforward og er opsummeret herunder.
Vi har indtil videre skrevet, at outputværdierne kan fortolkes som sandsynligheder. Men bare fordi at en række tal (\(o_1, o_2, \dots, o_J\)) alle ligger mellem 0 og 1 og alle summerer til 1, så er det jo ikke sikkert, at de på en fornuftig måde angiver sandsynligheden for de fire forskellige muligheder, som de enkelte elever har. For eksempel kunne de fleste lærere nok ønske sig, at
\[ o_1 = 0.5, \quad 0_2 = 0.5, \quad o_3=0, \quad o_4=0 \] fuldstændig uafhængig af svarene på de tre spørgsmål.
Det svarer til, at cirka halvdelen af elever bliver i klassen og regner opgaver, mens den anden halvdel sætter sig ud og regner. Til gengæld er der ingen, som går i kantinen og feder den, ligsom der heller ikke er nogle, som bare går hjem.
For at vores nye AI assistent skal give et nogenlunde retvisende billede af virkeligheden (det vil sige elevernes valg og ikke lærerens ønsker!) skal vi have fundet nogle outputværdier, som for det første afhænger af inputværdierne (man kan jo se på figur 1 at inputværdierne har indflydelse), og som for det andet rent faktisk giver en realistisk sandsynlighed for hver af de fire muligheder. Det gør vi ved at blive ved med at "skrue" på alle vægtene indtil, at de beregnede outputværdier i (5) giver et godt bud på sandsynlighederne for de 4 muligheder.
Hvordan, det rent faktisk lader sig gøre, kommer her.
Cross-entropy tabsfunktionen
Forestil dig, at vi bare har valgt nogle tilfældige værdier af vægtene. På den baggrund kan vi for et givent sæt af inputværdier beregne outputværdierne ved hjælp af feedforward-udtrykkene i (5). Vi vil som eksempel se på elev nummer 7 fra tabel 1. Denne elev har valgt mulighed 2 (gå uden for klassen for at regne opgaver) og har derfor targetværdi
\[ \vec t = \begin{pmatrix} 0 \\ 1 \\ 0 \\ 0 \\ \end{pmatrix} \tag{6}\]
En bestemt "indstilling" af vægtene kunne for eksempel give denne outputvektor:
\[ \vec o = \begin{pmatrix} 0.85 \\ 0.10 \\ 0.03 \\ 0.02 \\ \end{pmatrix} \tag{7}\]
Det svarer til, at vægtene ikke har fået nogle "gode" værdier, fordi denne outputvektor svarer til, at der kun er \(10 \%\) chance for at eleven vælger mulighed 2. Hvis vægtene i stedet havde haft værdier, som ville resultere i denne outputvektor
\[ \vec o = \begin{pmatrix} 0.10 \\ 0.85 \\ 0.03 \\ 0.02 \\ \end{pmatrix} \tag{8}\]
så vil vi straks være mere tilfredse med vores AI assistent, fordi sandsynligheden for mulighed 2 nu er steget til \(85 \%\). Faktisk vil vi allerhelst kunne vælge vægtene, så outputvektoren for elev nummer 7 kommer så tæt som muligt på targetvektoren i (6) – og noget tilsvarende skal gerne gøre sig gældende for de øvrige 11 elever i træningsdata.
Vi har derfor brug for en metode til at vælge vægtene, så outputvektoren i (8) bliver "belønnet" fremfor outputvektoren i (7). For at gøre det definerer man en såkaldt tabsfunktion. Vi vil her bruge en tabsfunktion, som kaldes for cross-entropy.
For at holde tingene simple starter vi med at se på ét træningseksempel ad gangen (til sidst generaliserer vi). Cross-entropy tabsfunktionen er defineret sådan her:
\[ E = - \sum_{j=1}^J t_j \cdot \ln(o_j) \]
Det ser måske lige lidt mærkeligt ud, men vi skal nok forklare det. Vi kan prøve at skrive summen ud:
\[ E = - \left (t_1 \cdot \ln(o_1) + t_2 \cdot \ln(o_2) + \cdots + t_j \cdot \ln(o_j) + \cdots + t_J \cdot \ln(o_J) \right) \]
Vi husker nu på, at \(\vec t\) er en one hot vektor. Det vil sige, at det kun er ét af \(t_j\)’erne i ovenstående, der er 1 – resten er 0. Lad os sige at det er \(t_j\), der er 1. Så er
\[ E = - t_j \cdot \ln(o_j) = - \ln(o_j). \]
I figur 5 har vi tegnet grafen for den naturlige logaritme-funktion samt grafen for minus den naturlige logartime-funktion:
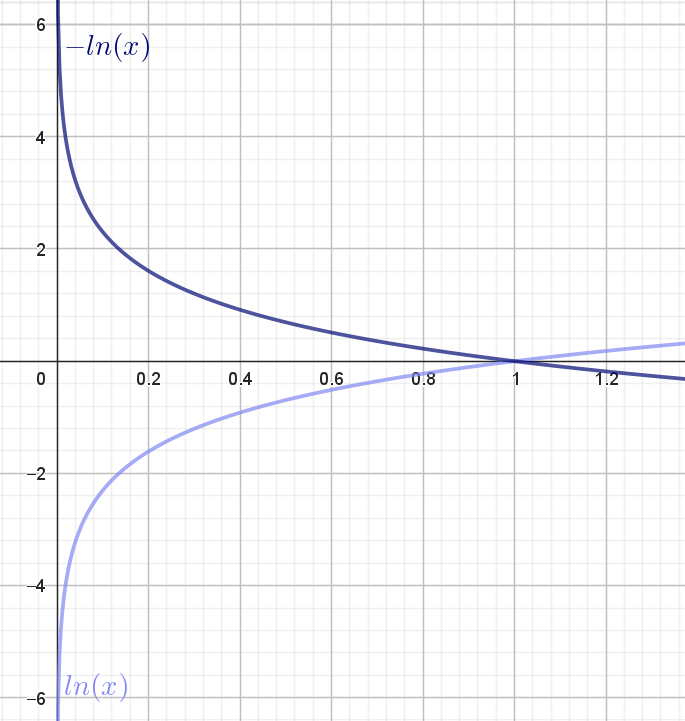
Da \(0<o_j<1\) kan vi for det første se, at \(-\ln(o_j) >0\). Det vil sige, at tabsfunktionen er positiv.
Husk nu på, at \(t_j=1\). Hvis vægtene i vores neurale netværk er "indstillet" godt, så skal \(o_j\) være tæt på 1. I figur 5 kan vi se, at det svarer til, at \(-\ln(o_j)\) er tæt på \(0\). Det betyder, at værdien af tabsfunktionen er lille. Omvendt hvis vægtene er "indstillet" dårligt, så \(o_j\) er tæt på \(0\) (selvom \(t_j=1\)), så vil \(-\ln(o_j)\) være et stort positivt tal. Altså er værdien af tabsfunktionen stor.
Det betyder, at tabsfunktionen på den måde måler "kvaliteten" af netværket:
For et godt netværk (med gode indstillinger af vægtene) vil tabsfunktionen have en lille, men positiv værdi.
For et dårligt netværk (med dårlige indstillinger af vægtene) vil tabsfunktionen have en stor positiv værdi.
Lad også illustrere det med det tidligere eksempel. Hvis
\[ \vec t = \begin{pmatrix} 0 \\ 1 \\ 0 \\ 0 \\ \end{pmatrix} \quad \textrm{og} \quad \vec o = \begin{pmatrix} 0.85 \\ 0.10 \\ 0.03 \\ 0.02 \\ \end{pmatrix} \]
så har vi et dårligt netværk og værdien af tabsfunktionen bliver
\[ \begin{aligned} E &= - \left( 0 \cdot \ln(0.85) + 1 \cdot \ln(0.10) + 0 \cdot \ln(0.03) + 0 \cdot \ln(0.02)\right) \\ &= - \ln(0.10) \approx 2.30. \end{aligned} \]
Har vi derimod et bedre netværk, som i stedet giver følgende outputvektor:
\[ \vec t = \begin{pmatrix} 0 \\ 1 \\ 0 \\ 0 \\ \end{pmatrix} \quad \textrm{og} \quad \vec o = \begin{pmatrix} 0.10 \\ 0.85 \\ 0.03 \\ 0.02 \\ \end{pmatrix} \]
så vil værdien af tabsfunktionen være
\[ \begin{aligned} E &= - \left( 0 \cdot \ln(0.10) + 1 \cdot \ln(0.85) + 0 \cdot \ln(0.03) + 0 \cdot \ln(0.02)\right) \\ &= - \ln(0.85) \approx 0.16. \end{aligned} \]
Altså kan vi her se, at det netværk, som er bedre, også har en lavere værdi af tabsfunktionen. Hele idéen er derfor, at vi for et givent træningsdatasæt vil bestemme de værdier af vægtene, som minimerer tabsfunktionen. Hvordan det gøres forklares i det næste afsnit.
Opdatering af vægtene
Vi skal bestemme de værdier af vægtene, som minimerer tabsfunktionen
\[ E = - \sum_{i=1}^J t_i \cdot \ln(o_i) \tag{9}\]
Husk på at outputværdierne \(o_i\) afhænger af \(z\)-værdierne via (5), mens \(z\)-værdierne afhænger af vægtene via (4). Altså afhænger tabsfunktionen også indirekte af alle vægtene.
Når man skal minimere en funktion, som afhænger af flere variable (her vægtene), kan man finde alle de partielle afledede og sætte dem lig med \(0\) (ligesom du sikkert er vant til, at løse \(f'(x)=0\), hvis du skal bestemme minimum for funktionen \(f\)). Det vil give lige så mange ligninger, som der er vægte, og desuden vil ligningerne være koblet med hinanden. Det betyder, at denne fremgangsmåde er beregningsmæssig tung og/eller vil kræve alt for meget plads på en computer. Derfor vælger man i stedet at bruge en approksimativ metode, som kaldes for gradientnedstigning. Vi vil her kort forklare, hvad det går ud på.
Hvis en funktion \(f\) afhænger af \(x_1, x_2, \dots, x_n\) så kaldes den vektor, som består af alle de partielle afledede for gradienten:
\[ \nabla f(x_1, x_2, \dots, x_n) = \begin{pmatrix} \frac{\partial f}{\partial x_1} \\ \frac{\partial f}{\partial x_2} \\ \vdots \\ \frac{\partial f}{\partial x_n} \end{pmatrix}. \]
Det viser sig, at denne gradient peger i den retning, hvor funktionsværdien vokser mest. Omvendt vil minus gradienten \(-\nabla f(x_1, x_2, \dots, x_n)\) pege i den retning, hvor funktionsværdien aftager mest. Hvis vi derfor står et vilkårligt sted på grafen for \(f\) og går et lille skridt i den negative gradientens retning, så vil vi være på vej ned mod et minimum (eventuelt kun lokalt). Når vi har gået det lille skridt, udregner vi gradienten igen og bevæger os igen et lille skridt i den negative gradients retning1. Sådan fortsætter man indstil funktionsværdien ikke ændrer sig ret meget – det svarer forhåbentlig til, at vi har fundet et (lokalt) minimum.
1 Du kan tænke på minus gradienten som et kompas, der hele tiden viser dig, hvilken vej du skal gå for at bevæge dig ned mod et minimum.
Nu hedder vores funktion ikke \(f\), men \(E\), og \(E\) afhænger af alle vægtene \(w_{j,k}\). Derfor, når vægten \(w_{j,k}\) skal opdateres, så gør vi følgende:
\[ w_{j,k}^{\textrm{ny}} \leftarrow w_{j,k} - \eta \cdot \frac{\partial E}{\partial w_{j,k}}. \tag{10}\]
Tallet \(\eta\) kaldes for en learning rate og er typisk et lille tal mellem \(0\) og \(1\). Det svarer til den skridtlængde vi bruger, når vi går i den negative gradients retning.
Det vil sige for at opdatere \(w_{j,k}\)-vægten, skal vi have udregnet den partielle afledede
\[ \frac{\partial E}{\partial w_{j,k}}. \]
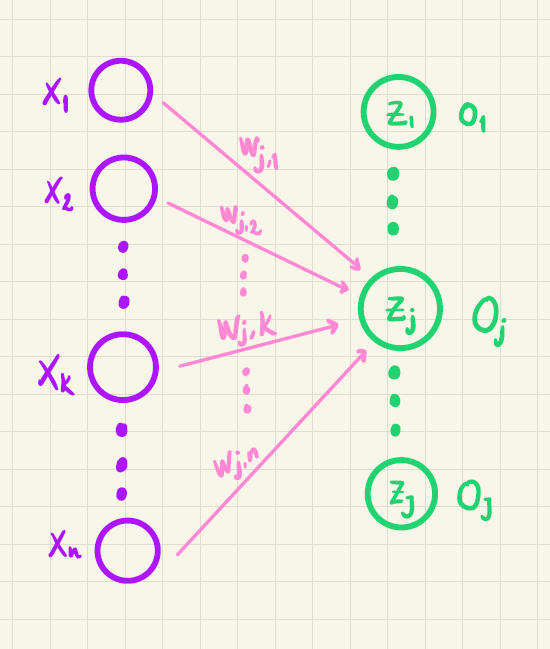
Hvis vi ser på figur 6 og (4) kan vi se, at \(w_{j,k}\) kun har indflydelse på \(z_j\). Til gengæld har alle \(z\)-værdierne indflydelse på alle \(o\)-værdierne på grund af udtrykket i (5).
Derfor kan vi ved hjælp af kædereglen for flere variable finde den partielle afledede af \(E\) med hensyn til \(w_{j,k}\) på denne måde
\[ \frac{\partial E}{\partial w_{j,k}} = \sum_{i=1}^J \frac{\partial E}{\partial z_i} \cdot \frac{\partial z_i}{\partial w_{j,k}} \]
Men da \(w_{j,k}\) kun har indflydelse på \(z_j\) (jævnfør figur 6 og (4)), så vil
\[ \frac{\partial z_i}{\partial w_{j,k}}=0 \qquad \text{når} \qquad i \neq j \]
og derfor kan vi nøjes med følgende forsimplede udtryk:
\[ \frac{\partial E}{\partial w_{j,k}} = \frac{\partial E}{\partial z_j} \cdot \frac{\partial z_j}{\partial w_{j,k}} \tag{11}\]
Vi starter med at regne på den sidste faktor \(\frac{\partial z_j}{\partial w_{j,k}}\) (fordi den er nemmest!). Ifølge (4) er
\[ \begin{aligned} \frac{\partial z_j}{\partial w_{j,k}} &= \frac{\partial }{\partial w_{j,k}} \left ( w_{j,0} + w_{j,1} \cdot x_1 + w_{j,2} \cdot x_2 + \cdots + w_{j,k} \cdot x_k + \cdots + w_{j,n} \cdot x_n \right) \\ &= x_k \end{aligned} \tag{12}\]
Bemærk, at hvis vi differentierer med hensyn til \(w_{j,0}\) så er
\[ \frac{\partial z_j}{\partial w_{j,0}} = 1. \] Men definerer vi en ekstra inputværdi \(x_0\), som altid er \(1\), så gælder udtrykket i (12) stadigvæk – også når \(k=0\).
For at bestemme den første faktor \(\frac{\partial E}{\partial z_j}\) bruger vi definitionen af tabsfunktionen i (9) og differentierer ledvist:
\[ \frac{\partial E}{\partial z_j} = - \sum_{i=1}^J t_i \cdot \frac{1}{o_i} \cdot \frac{\partial o_i}{\partial z_j}, \tag{13}\]
hvor vi har brugt kædereglen og, at \(\ln(o_i)\) differentieret er \(\frac{1}{o_i}\).
Nu er
\[ o_i = \frac{\mathrm{e}^{z_i}}{\sum_{l=1}^J \mathrm{e}^{z_l}}. \]
Da \(o_i\) er udtrykt ved en brøk, får vi brug for kvotientreglen, når vi skal differentiere \(o_i\):
\[ \left ( \frac{f}{g} \right )'(x)= \frac{f'(x) \cdot g(x) - f(x) \cdot g'(x)}{(g(x))^2} \]
Når \(o_i\) skal differentieres med hensyn til \(z_j\), er der to muligheder alt efter om \(i=j\) eller \(i \neq j\).
Hvis \(i \neq j\), får vi
\[ \begin{aligned} \frac{\partial o_i}{\partial z_j} &= \frac{0 \cdot (\sum_{l=1}^J \mathrm{e}^{z_l}) - \mathrm{e}^{z_i} \cdot \mathrm{e}^{z_j}}{\left ( \sum_{l=1}^J \mathrm{e}^{z_l} \right )^2} \\ &= - \frac{\mathrm{e}^{z_i}}{\sum_{l=1}^J \mathrm{e}^{z_l}} \cdot \frac{\mathrm{e}^{z_j}}{\sum_{l=1}^J \mathrm{e}^{z_l}} = - o_i \cdot o_j, \quad \quad i \neq j \end{aligned} \]
hvor sidste lighedstegn følger af definitionen i (5).
Hvis \(i=j\), får vi
\[ \begin{aligned} \frac{\partial o_i}{\partial z_j} &= \frac{\partial o_j}{\partial z_j} = \frac{\mathrm{e}^{z_j} \cdot (\sum_{l=1}^J \mathrm{e}^{z_l}) - \mathrm{e}^{z_j} \cdot \mathrm{e}^{z_j}}{\left ( \sum_{l=1}^J \mathrm{e}^{z_l} \right )^2} \\ &= \frac{\mathrm{e}^{z_j} \cdot (\sum_{l=1}^J \mathrm{e}^{z_l})}{\left ( \sum_{l=1}^J \mathrm{e}^{z_l} \right )^2} - \frac{(\mathrm{e}^{z_j})^2}{\left ( \sum_{l=1}^J \mathrm{e}^{z_l} \right )^2} \\ &= \frac{\mathrm{e}^{z_j}}{\sum_{l=1}^J \mathrm{e}^{z_l}} - \left ( \frac{\mathrm{e}^{z_j}}{\sum_{l=1}^J \mathrm{e}^{z_l}} \right)^2 \\ & = o_j-o_j^2 = o_j(1-o_j), \quad \quad i = j \end{aligned} \]
Vi kan nu indsætte i (13):
\[ \begin{aligned} \frac{\partial E}{\partial z_j} &= - \left ( \sum_{\substack{i=1 \\ i \neq j }}^J t_i \cdot \frac{1}{o_i} \cdot (-o_i \cdot o_j) \right ) - t_j \cdot \frac{1}{o_j} \cdot o_j \cdot (1-o_j) \\ &= - \left ( \sum_{\substack{i=1 \\ i \neq j }}^J t_i \cdot (-o_j) \right ) - t_j \cdot (1-o_j) \\ &= \left ( \sum_{\substack{i=1 \\ i \neq j }}^J t_i \cdot o_j \right ) - t_j + t_j \cdot o_j \end{aligned} \]
Vi kan nu se, at det led \(t_j \cdot o_j\), som ikke er med i den første sum (hvor \(i \neq j\)), fremkommer som sidste led i ovenstående udtryk. Derfor kan vi inkludere dette led i den første sum og få:
\[ \begin{aligned} \frac{\partial E}{\partial z_j} &= \left (\sum_{i=1}^J t_i \cdot o_j \right ) - t_j \\ & = \left (o_j \cdot \sum_{i=1}^J t_i \right ) - t_j, \end{aligned} \]
hvor sidste lighedstegn følger af, at \(o_j\) ikke afhænger af det indeks, vi summerer over, og derfor kan \(o_j\) sættes ud foran summen (det svarer til at sætte en fællesfaktor ud foran en parentes).
Vi udnytter nu, at \(\vec t\) er en one hot vektor – det vil sige, at \(\sum_{i=1}^J t_i = 1\). Derfor ender vi med det meget simple udtryk
\[ \frac{\partial E}{\partial z_j} = o_j - t_j = -(t_j-o_j) \]
Vi indsætter i (11) og får
\[ \frac{\partial E}{\partial w_{j,k}} = \underbrace{-(t_j - o_j)}_{\frac{\partial E}{\partial z_j}} \cdot \underbrace{x_k}_{\frac{\partial z_j}{\partial w_{j,k}}} \tag{14}\]
Bruger vi opdateringsreglen for \(w_{j,k}\)-vægten i (10), ender vi med følgende:
Vægten fra det \(k\)’te input \(x_k\) til den \(j\)’te outputneuron opdateres således:
\[ w_{j,k}^{(\textrm{ny})} \leftarrow w_{j,k} + \eta \cdot (t_j - o_j) \cdot x_k \]
hvor \(x_k=1\), hvis \(k=0\).
Opdatering ved hjælp af hele træningsdatasættet
I det ovenstående har vi udledt opdateringsreglen for \(w_{j,k}\)-vægten baseret ét enkelt træningseksempel ad gangen ved at finde minimum for tabsfunktionen:
\[ E = - \sum_{i=1}^J t_i \cdot \ln(o_i) \]
I virkeligheden definerer man tabsfunktionen baseret på hele træningsdatasættet. Vi starter med at nummerere træningsdata fra \(1\) til \(M\) og kalder targetværdien og outputværdien hørende til det \(m\)’te træningseksempel for \(\vec t^{(m)}\) og \(\vec o^{(m)}\):
\[ \vec t^{(m)} = \begin{pmatrix} t_1^{(m)} \\ t_2^{(m)} \\ \vdots \\ t_J^{(m)} \\ \end{pmatrix} \quad \quad \textrm{og} \quad \quad \vec o^{(m)} = \begin{pmatrix} o_1^{(m)} \\ o_2^{(m)} \\ \vdots \\ o_J^{(m)} \\ \end{pmatrix} \]
Så definerer man tabsfunktionen på denne måde:
\[ E = \sum_{m=1}^M \left (- \sum_{i=1}^J t_i^{(m)} \cdot \ln(o_i^{(m)}) \right ) \] Og sætter vi
\[ E^{(m)} = - \sum_{i=1}^J t_i^{(m)} \cdot \ln(o_i^{(m)}) \] så bliver tabsfunktionen bare en sum over de individuelle bidrag til tabsfunktionen fra hvert træningseksempel:
\[ E = \sum_{m=1}^M E^{(m)} \] Vi kan heldigvis differentiere ledvist og får derfor
\[ \frac{\partial E}{\partial w_{j,k}} = \sum_{m=1}^M \frac{\partial E^{(m)}}{\partial w_{j,k}} \] I det foregående afsnit var det netop \(\frac{\partial E^{(m)}}{\partial w_{j,k}}\) vi udledte i (14) – dog uden at specificere nummeret på træningseksemplet:
\[ \frac{\partial E^{(m)}}{\partial w_{j,k}} = -(t_j^{(m)} - o_j^{(m)}) \cdot x_k^{(m)} \]
Derfor bliver \[ \frac{\partial E}{\partial w_{j,k}} = \sum_{m=1}^M \frac{\partial E^{(m)}}{\partial w_{j,k}} = - \sum_{m=1}^M (t_j^{(m)} - o_j^{(m)}) \cdot x_k^{(m)} \] Opdateringsreglen for \(w_{j,k}\)-vægten bliver i det tilfælde:
Vægten fra det \(k\)’te input \(x_k\) til den \(j\)’te outputneuron opdateres således:
\[ w_{j,k}^{(\textrm{ny})} \leftarrow w_{j,k} + \eta \cdot \sum_{m=1}^M (t_j^{(m)} - o_j^{(m)}) \cdot x_k^{(m)} \]
hvor \(x_k^{(m)}=1\), hvis \(k=0\).
Samlet set trænes netværket på denne måde:
Sæt alle vægtene til en tilfældig værdi og vælg en værdi for learning raten \(\eta\).
For alle træningseksempler udregnes \(z_j^{(m)}\) og \(o_j^{(m)}\) ved hjælp af feedforward-udtrykkene:
\[ z_j^{(m)} = w_{j,0} + w_{j,1} \cdot x_1^{(m)} + w_{j,2} \cdot x_2^{(m)} + \cdots + w_{j,n} \cdot x_n^{(m)} \]
og
\[ o_j^{(m)} = \frac{\mathrm{e}^{z_j^{(m)}}}{\sum_{i=1}^J \mathrm{e}^{z_i^{(m)}}} \]
for \(j=1, 2, \dots, J\).
Opdatér alle vægtene:
\[ w_{j,k}^{(\textrm{ny})} \leftarrow w_{j,k} + \eta \cdot \sum_{m=1}^M (t_j^{(m)} - o_j^{(m)}) \cdot x_k^{(m)} \]
Alle vægtene er nu opdateret, og vi kan gentage punkt 2 og 3, hvor feedforward i 2 hver gang er baseret på de netop opdaterede vægte fra det foregående gennemløb. Opdateringen af vægtene fortsætter indtil værdien af tabsfunktionen næsten ikke ændrer sig. Håbet er nu, at vi har fundet et minimum (eventuelt kun lokalt) for tabsfunktionen.
Tilbage til eksemplet
Vi har nu fået udledt opdateringsreglerne for alle vægtene, og vi vil derfor prøve at træne et netværk ved hjælp af træningsdata i tabel 1. Hvis vi til start sætter alle vægtene til \(0.5\), vælger en learning rate på \(0.001\) og laver i alt \(100000\) iterationer (det vil sige, at vægtene alt i alt opdateres \(100000\) gange), så nærmer vi os et minimum for tabsfunktionen. Alle outputværdierne kan nu beregnes ved hjælp af (5). Gør vi det for alle data i træningsdatasættet, får vi følgende2:
2 Bemærk, at hvis \(o_1+o_2+o_3+ o_4\) ikke giver \(1\), så skyldes det afrunding.
| Elev nr. | \(x_1\) (søvn) | \(x_2\) (emne) | \(x_3\) (eksamen) | Valg | \(o_1\) | \(o_2\) | \(o_3\) | \(o_4\) |
|---|---|---|---|---|---|---|---|---|
| \(1\) | \(10\) | \(10\) | \(10\) | \({\color{#020873} 1}\) | \(0.98\) | \(0.02\) | \(0.00\) | \(0.00\) |
| \(2\) | \(8\) | \(7\) | \(8\) | \({\color{#020873} 1}\) | \(0.50\) | \(0.50\) | \(0.00\) | \(0.00\) |
| \(3\) | \(9\) | \(6\) | \(10\) | \({\color{#020873} 1}\) | \(0.76\) | \(0.23\) | \(0.00\) | \(0.00\) |
| \(4\) | \(4\) | \(10\) | \(10\) | \({\color{#020873} 1}\) | \(0.77\) | \(0.23\) | \(0.00\) | \(0.00\) |
| \(5\) | \(5\) | \(8\) | \(7\) | \({\color{#8086F2} 2}\) | \(0.19\) | \(0.81\) | \(0.00\) | \(0.00\) |
| \(6\) | \(10\) | \(7\) | \(4\) | \({\color{#8086F2} 2}\) | \(0.15\) | \(0.85\) | \(0.00\) | \(0.00\) |
| \(7\) | \(7\) | \(7\) | \(10\) | \({\color{#8086F2} 2}\) | \(0.70\) | \(0.30\) | \(0.00\) | \(0.00\) |
| \(8\) | \(8\) | \(3\) | \(4\) | \({\color{#F2B33D} 3}\) | \(0.00\) | \(0.00\) | \(0.98\) | \(0.02\) |
| \(9\) | \(6\) | \(2\) | \(5\) | \({\color{#F2B33D} 3}\) | \(0.00\) | \(0.00\) | \(0.99\) | \(0.01\) |
| \(10\) | \(10\) | \(2\) | \(2\) | \({\color{#F2B33D} 3}\) | \(0.00\) | \(0.00\) | \(1.00\) | \(0.00\) |
| \(11\) | \(1\) | \(1\) | \(3\) | \({\color{#F288B9} 4}\) | \(0.00\) | \(0.02\) | \(0.00\) | \(0.98\) |
| \(12\) | \(5\) | \(2\) | \(2\) | \({\color{#F288B9} 4}\) | \(0.00\) | \(0.02\) | \(0.02\) | \(0.96\) |
Et netværk vil altid være forholdsvis godt til at prædiktere korrekt på de data, som netværket er trænet på. Det kan du læse mere om i noten om Overfitting, modeludvælgelse og krydsvalidering. Med det i baghovedet kan vi alligevel se fra tabel 2, at den prædikterede sandsynlighed for det valg, som hver elev træffer, er høj. For eksempel vælger elev nr. 1 også valg 1 (at blive i klassen), og den prædikterede sandsynlighed for dette valg er \(o_1 = 0.98\).
For elev nr. 2 kan vi se, at vores AI assistent er i tvivl om (\(o_1=o_2=0.50\)), om den skal prædiktere valg 1 eller 2 (eleven har valgt 1). For elev nr. 7 vil vores AI assistent prædiktere valg 1 (\(o_1 = 0.70\)), men eleven træffer i virkeligheden valg 2. De resterende anbefalinger er korrekte.
På figur 7 er elev 2 og 7 fremhævet ved, at de tilhørende punkter er tegnet større. Hvis man drejer lidt rundt på figuren, kan man se, at de to punkter ligger forholdsvis tæt på hinanden og i nærheden af andre mørkeblå punkter, så det er ikke helt så underligt, at netværket netop har svært ved at prædiktere, som det gør.
Nu er idéen jo ikke at komme med et godt råd til de elever, som allerede har truffet et valg (svarende til at prædiktere på træningsdata), men derimod at læreren får et værktøj til at vejlede kommende elever.
Byd derfor velkommen til tre nye elever:
Den første elev, som træder ind ad døren er Anton. Anton har sovet fuldstændig fantastisk (\(x_1=10\)), han synes, at det emne, vi er i gang med, er pænt kedeligt (\(x_2=2\)). Til gengæld har Anton høje ambitioner om at klare sig godt til eksamen (\(x_3=9\)).
Herefter følger Signe. Signe bøvler lidt med sin søvn (\(x_1=4\)), hun synes, at emnet vi er i gang med er semi godt \(x_2=5\), og så har Signe skyhøje forventninger til eksamen (\(x_3=10\)).
Til sidst kommer Mads – lidt for sent i øvrigt… Mads har nemlig spillet computer den halve nat (\(x_1=3\)), han synes, at emnet er ret interessant (\(x_2=8\)), men han er pænt ligeglad med, hvordan det går til eksamen (\(x_3=2\)).
Ved timens start svarer alle tre elever straks på de tre spørgsmål, som læreren indtaster i sin AI assistent. Her er, hvad der kommer ud af det:
| Elev | \(x_1\) | \(x_2\) | \(x_3\) | \(o_1\) | \(o_2\) | \(o_3\) | \(o_4\) | Valg |
|---|---|---|---|---|---|---|---|---|
| Anton | \(10\) | \(2\) | \(9\) | \(0.00\) | \(0.00\) | \(1.00\) | \(0.00\) | \({\color{#F2B33D} 3}\) |
| Signe | \(4\) | \(5\) | \(10\) | \(0.17\) | \(0.82\) | \(0.00\) | \(0.00\) | \({\color{#8086F2} 2}\) |
| Mads | \(3\) | \(8\) | \(2\) | \(0.00\) | \(1.00\) | \(0.00\) | \(0.00\) | \({\color{#8086F2} 2}\) |
Det prædikteres, at Anton vil gå i kantinen (valg 3), mens Signe og Mads vil gå ud for at regne opgaver (valg 2). Læreren ved derfor nu, at hun skal være ekstra opmærksom på Anton.
Det kan godt se ud som om, at \(x_2\) (interessen for emnet) er forholdsvis afgørende for den endelig anbefaling. Hvis du tager et kig på figur 1, vil du også opdage, at hvis \(x_2<5\), så er alle punkter lyserøde eller gule (svarende til valg 3 og 4), mens alle punkter, hvor \(x_2 \geq 5\) er lyse- eller mørkeblå (valg 1 og 2). Det kunne jo få en til at tænke, om det i virkeligheden ville være nok at svare på spørgsmål 2, uden at det går udover klassifikationsnøjagtigheden. Det vil man kunne undersøge ved at lave en model med kun \(x_2\) som inputvariabel og en anden model med alle tre inputvariable og så for eksempel vurdere de to modellers klassifikationsnøjagtighed ved hjælp af krydsvalidering, men det ligger uden for formålet med denne note.
I figur 8 er de tre nye elever indtegnet sammen med træningsdata. Når man ser, hvordan de tre nye elever ligger i forhold til de andre punkter i træningsdata, så giver det faktisk god mening, at Anton bliver "farvet" gul, mens Signe og Mads bliver "farvet" lyseblå.