Support Vector Machines
Denne note handler om Support Vector Machines, som er en metode inden for kunstig intelligens, der kan bruges til at adskille forskellige grupper fra hinanden.
Klassifikation ved hjælp af rette linjer
Som motiverende eksempel ser vi på et af de steder, hvor kunstig intelligens forventes at have stort potentiale, nemlig inden for personlig medicin. Når en læge behandler en patient med et lægemiddel, er det ikke altid, at lægemidlet har en effekt. Det formodes at skyldes biologiske forhold i kroppen så som patientens gener. Da de fleste lægemidler har bivirkninger, vil det som regel være bedst at spare patienten for behandling, hvis der alligevel ikke forventes en effekt. Lægen vil derfor gerne kunne forudsige på forhånd, om en patient har gavn af lægemidlet eller ej. For at finde ud af det, tager lægen nogle blodprøver og bestemmer nogle biomarkører. Biomarkører er mål for blodets indhold af bestemte stoffer, der for eksempel siger noget om patientens genetik eller overordnede helbred.
Ovenstående er et eksempel på et klassifikationsproblem. Lægen vil gerne kunne inddele patienterne i to grupper, nemlig "effekt" og "ikke effekt". Grupperne kalder vi også for klasser, og for nemheds skyld vil vi bare betegne de to klasser med \(1\) og \(-1\). Vi lader \(t\) være en variabel, der angiver klassen, det vil sige \(t\in \{-1,1\}\). Vi forestiller os desuden, at lægen måler to biologiske markører hos patienterne, som vi vil kalde \(x_1\) og \(x_2\). I forbindelse med kunstig intelligens kalder man \(x_1\) og \(x_2\) for features eller inputvariable, mens man kalder \(t\) for target (det er den værdi, vi gerne vil "ramme").
Vi ønsker at finde en klassifikationsalgoritme, der kan prædiktere (altså forudsige) klassen ud fra målinger af \(x_1\) og \(x_2\). For at hjælpe os med det, tager vi udgangspunkt i et træningsdatasæt bestående af \(n\) patienter, der er blevet behandlet med lægemidlet og har fået målt de to biomarkører \(x_1\) og \(x_2\). Desuden har vi observeret, om lægemidlet havde en effekt. Vi har altså et datasæt på formen vist i tabel 1, hvor hver række svarer til en patient:
| Patient | \(x_1\) | \(x_2\) | \(t\) |
|---|---|---|---|
| 1 | \(x_{1}^{(1)}\) | \(x_{2}^{(1)}\) | \(t^{(1)}\) |
| 2 | \(x_{1}^{(2)}\) | \(x_{2}^{(2)}\) | \(t^{(2)}\) |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | |
| \(n\) | \(x_{1}^{(n)}\) | \(x_{2}^{(n)}\) | \(t^{(n)}\) |
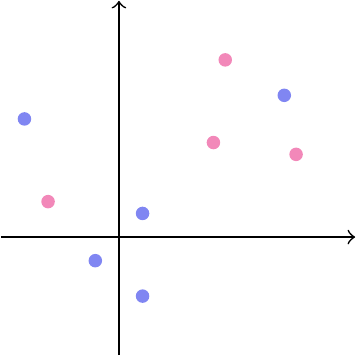
På figur 1 betragter vi et fiktivt datasæt. Vi har indtegnet punkterne \(\big(x_{1}^{(i)},x_{2}^{(i)}\big)\) i et koordinatsystem for syv patienter \(i=1,\ldots,7\). Hvert punkt er farvet lyserødt hvis \(t^{(i)}=1\) (lægemidlet har en effekt) og lyseblåt hvis \(t^{(i)}=-1\) (ingen effekt).
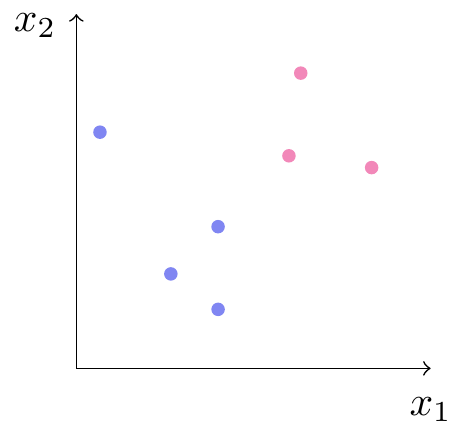
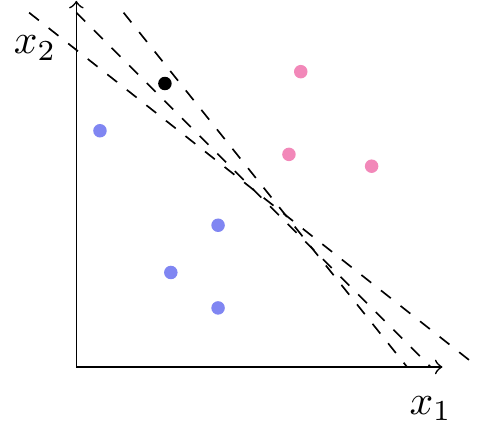
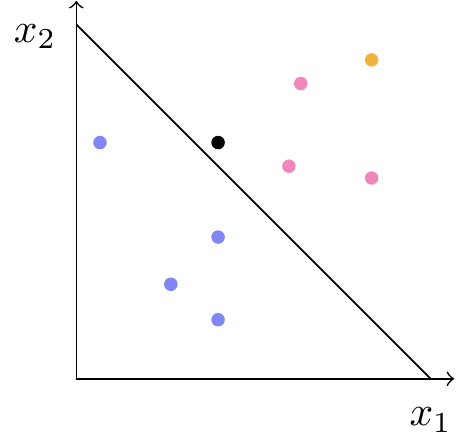
Hvis vi nu kommer med en ny patient, som har fået målt \(x_1\) og \(x_2\), vil vi gerne kunne klassificere den. Hvis den nye observation er placeret ved det hvide punkt på figur 2, vil det være naturligt at klassificere den som lyseblå. Er den placeret ved det gule punkt, vil det være oplagt at klassificere den som lyserød. Men hvis den er placeret ved det sorte punkt, er det ikke helt så klart, hvad vi skal vælge.
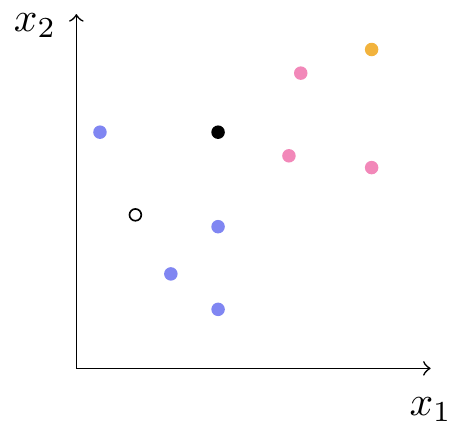
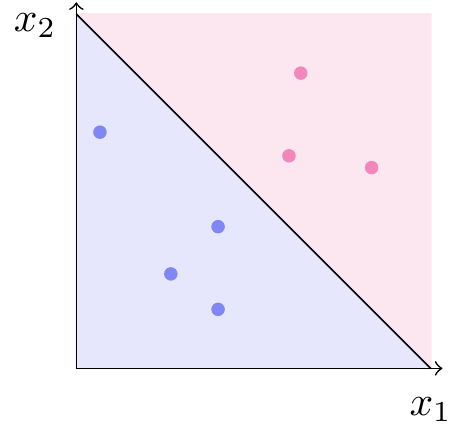
Idéen med support vector machines er at tegne en linje, der adskiller de to klasser. Et nyt punkt klassificeres som lyseblåt, hvis det ligger på den ene side, og som lyserødt, hvis det ligger på den anden side. Det deler planen op i to klassifikationsområder, som indikeret på figur 3.
Som vist på figur 4 er der mange måder at tegne sådan en skillelinje på. Klassifikationen af det sorte punkt afhænger af, hvor man placerer linjen.
Så hvordan vælger vi, hvor vi skal tegne linjen?
Support vector machines vælger den linje, der har størst mulig afstand til den nærmeste observation.
Hvordan det gøres i praksis, ser vi på i næste afsnit.
Support Vector Machines algoritmen
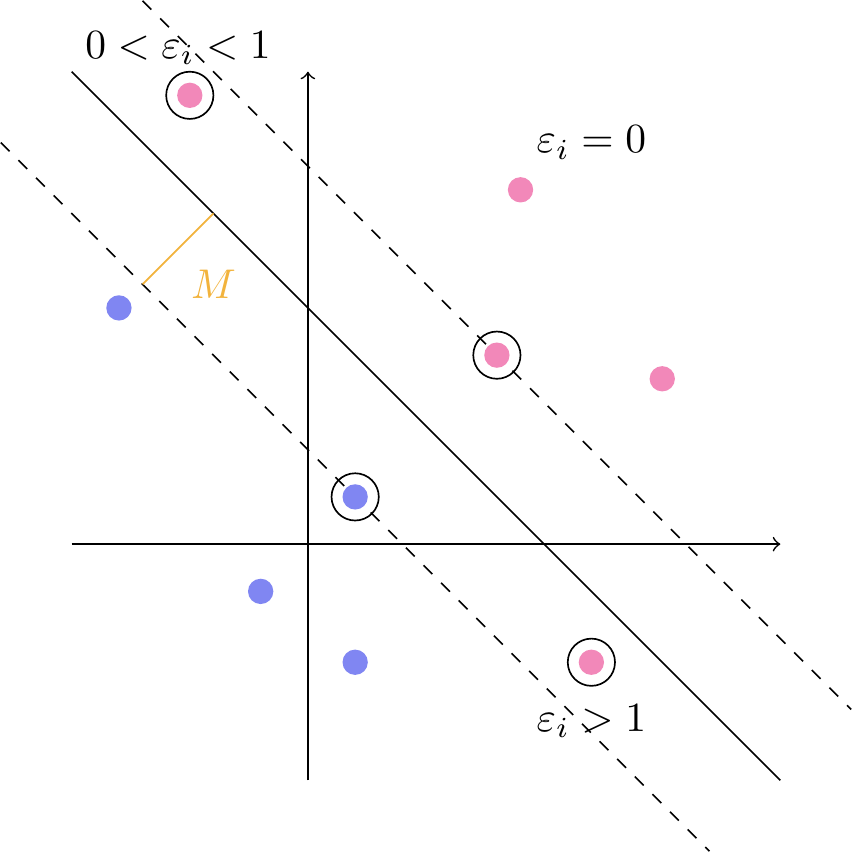
Afstanden fra en skillelinje til det nærmeste observerede punkt betegnes \(M\). I et bånd af bredde \(M\) på begge sider af linjen vil der altså ikke ligge nogen punkter. Dette bånd kalder vi linjens margin. Det er illustreret på figur 5.
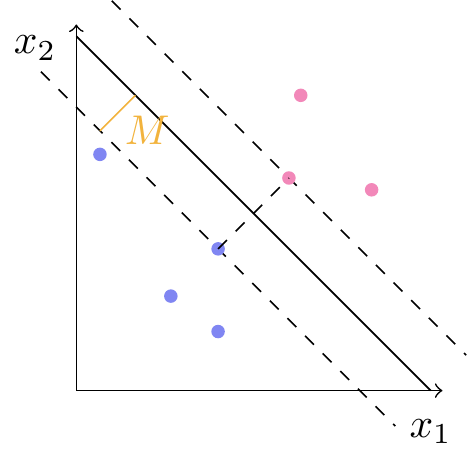
De punkter, som ligger på en af de stiplede linjer i figur 5, kaldes for supportvektorer — deraf navnet support vector machine.
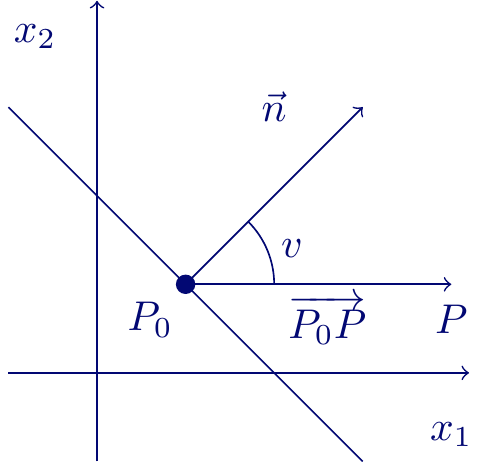
Hvordan finder vi så linjen med bredest mulig margin? Først får vi brug for lidt teori om afstanden fra et punkt til en linje. Husk på, at vi kan skrive ligningen for linjen \(l\) som
\[ l: ax_1 + bx_2 + c = 0 \]
hvor \(a\), \(b\) og \(c\) er konstanter, som skal fastlægges for at kende linjen. Vær opmærksom på, at du er vant til at se ligningen på denne måde:
\[ l: ax + by + c = 0 \]
Vektoren \[\vec{n} = \begin{pmatrix} a\\ b \end{pmatrix} \tag{1}\] er en normalvektor til linjen. I ved fra gymnasieundervisningen, at hvis \(P = (z_1,z_2)\) er et punkt i planen, så er afstanden fra \(P\) til linjen \(l\) givet ved
\[ \textrm{dist}(P,l)=\frac{|az_1 + bz_2 + c|}{\sqrt{a^2+b^2}} \]
Følgende sætning viser, at fortegnet på \(az_1 + bz_2 + c\) fortæller, hvilken side af linjen \(P\) ligger på.
Sætning 1 Hvis \(az_1 + bz_2 + c>0\), så ligger punktet \(P = (z_1,z_2)\) på den side af linjen, som \(\vec{n} = \begin{pmatrix} a\\ b \end{pmatrix}\) peger mod, og hvis \(az_1 + bz_2 + c<0\), så ligger punktet på modsat side.
På figur 6 er det illustreret, at \(ax_1 + bx_2 +c\) er positiv på den lyserøde side af linjen, som også er den side \(\vec{n}\) peger mod, mens \(ax_1 + bx_2 +c\) er negativ på den lyseblå side.
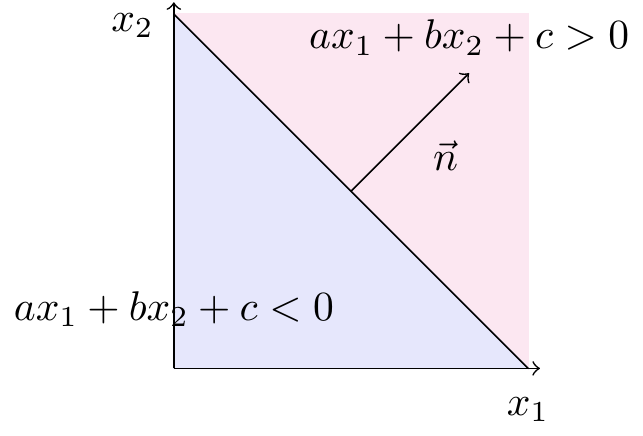
Beviset minder om beviset for afstanden fra punkt til linje, blot holder vi bedre øje med fortegn.
Vi kan benytte sætningen til at lave vores klassifikationsalgoritme. Lad os lægge os fast på, at vi ønsker en ligning for linjen på formen \(ax_1 + bx_2 +c = 0\), hvor normalvektoren peger i retning af den lyserøde klasse (\(t=1\)).
Vi ser nu på data \(\big(x_{1}^{(i)},x_{2}^{(i)},t^{(i)}\big)\) for den \(i\)te patient. Der er nu to muligheder:
Mulighed 1 (\(t=1\))
Hvis \(t^{(i)}=1\), så skal punktet \(\big(x_{1}^{(i)},x_{2}^{(i)}\big)\) ligge på samme side af linjen som normalvektoren. Vi vil derfor gerne have, at
\[ ax_{1}^{(i)} + bx_{2}^{(i)} + c >0 \]
Mulighed 2 (\(t=-1\))
Hvis derimod \(t^{(i)}=-1\), skal
\[ ax_{1}^{(i)} + bx_{2}^{(i)} + c < 0 \]
Hvis patienten er klassificeret rigtigt, skal \(t^{(i)}\) og \(ax_{1}^{(i)} + bx_{2}^{(i)} + c\) altså have samme fortegn. Det kan vi skrive kort som
\[ t^{(i)} \cdot \big(ax_{1}^{(i)} + bx_{2}^{(i)} + c\big) > 0 \]
idet produktet \(a \cdot b\) af to tal \(a\) og \(b\) er positivt, hvis og kun hvis \(a\) og \(b\) har samme fortegn.
Da et positivt tal er lig sin numeriske værdi, og \(t^{(i)}\) er enten \(1\) eller \(-1\), har vi desuden
\[ t^{(i)} \cdot \big(ax_{1}^{(i)} + bx_{2}^{(i)} + c\big)=\big|t_i^{(i)}\big(ax_{1}^{(i)} + bx_{2}^{(i)} + c\big)\big| = \big|ax_{1}^{(i)} + bx_{2}^{(i)} + c\big|. \]
Vi kan derfor skrive afstanden fra punktet \((x_{1}^{(i)},x_{2}^{(i)})\) til linjen \(l\) som
\[\textrm{dist}\big(\big(x_{1}^{(i)},x_{2}^{(i)}\big),l\big) = \frac{\big|ax_{1}^{(i)} + bx_{2}^{(i)} + c\big|}{\sqrt{a^2+b^2}} =\frac{t^{(i)} \cdot \big(ax_{1}^{(i)} + bx_{2}^{(i)} + c\big)}{\sqrt{a^2+b^2}} \]
Hvis vores linje skal have en margin på \(M>0\), skal denne afstand være mindst \(M\), det vil sige
\[ \textrm{dist}\big(\big(x_{1}^{(i)},x_{2}^{(i)}\big),l\big) =\frac{t^{(i)} \cdot (ax_{1}^{(i)} + bx_{2}^{(i)} + c\big)}{\sqrt{a^2+b^2}}\geq M>0. \tag{2}\]
Bemærk, at denne ulighed både sikrer, at punktet ligger på den rigtige side af linjen (da \(t^{(i)} \cdot (ax_{1}^{(i)} + bx_{2}^{(i)} + c)\) er nødt til at være positiv), og at afstanden til linjen er mindst \(M\).
For at finde en linje, der klassificerer alle vores punkter korrekt med en margin af bredde \(M\), skal (2) være opfyldt for alle punkter. For at finde linjen med maksimal margin, skal vi derfor løse følgende optimeringsproblem:
Support Vector Machine i planen – optimeringsproblem
Find \(a,b,c\in \mathbb{R}\) og \(M>0\), der maksimerer \(M\) under betingelserne
\[ \frac{t_i^{(i)} \cdot \big(ax_{1}^{(i)} + bx_{2}^{(i)} + c\big)}{\sqrt{a^2+b^2}}\geq M\qquad \text{ for alle } i=1,\ldots,n \tag{3}\]
Dette er et såkaldt betinget optimeringsproblem. Man kan tænke på det som en funktion \(f(a,b,c,M)=M\), der skal maksimeres. Ulighederne i (3) lægger nogle begrænsninger på definitionsmængden for \(f\). Der er altså tale om optimering af en funktion på en begrænset definitionsmængde. Her afhænger funktionen dog ikke bare af en enkelt variabel, som I kender det fra gymnasieundervisningen, men af hele fire variable \(a,b,c,M\), hvilket gør definitionsmængden kompliceret. Denne type problemer må derfor løses numerisk. Nedenfor viser vi, hvordan det gøres i Excel.
Når linjen er fundet, kan vi begynde at prædiktere effekten af lægemidlet for nye patienter. Vi måler patientens biomarkører \((x_1,x_2)\). Vi beregner så \(ax_1+bx_2+c\). Hvis \(ax_1+bx_2+c>0\) prædikterer vi klasse \(1\), altså at lægemidlet har en effekt. Hvis \(ax_1+bx_2+c<0\) prædikterer vi klasse \(-1\) og dermed, at lægemidlet ikke har effekt.
Løsning med Excel
Som vi har formuleret vores optimeringsproblem indtil videre, har det mere end én løsning. Vi ville derfor få en fejlmeddelelse fra Excel, hvis vi prøvede at løse det direkte. For at se hvorfor, kan vi prøve at gange \(a,b\) og \(c\) med et \(s>0\). Da bliver tælleren i (3) til
\[ t^{(i)} \cdot \big(sax_{1}^{(i)} + sbx_{2}^{(i)} + sc\big) = s \cdot t^{(i)} \cdot \big(ax_{1}^{(i)} + bx_{2}^{(i)} + c\big) \]
Nævneren bliver
\[ \begin{aligned} \sqrt{(sa)^2 + (sb)^2} &=\sqrt{s^2a^2 + s^2b^2}=\sqrt{s^2(a^2+b^2)} \\ &= \sqrt{s^2}\sqrt{a^2+b^2}=s\sqrt{a^2+b^2} \end{aligned} \]
Hele brøken bliver
\[ \begin{aligned} \frac{t^{(i)} \cdot \big(sax_{1}^{(i)} + sbx_{2}^{(i)} + sc\big)}{\sqrt{(sa)^2+(sb)^2}} &=\frac{s \cdot t^{(i)} \cdot \big(ax_{1}^{(i)} + bx_{2}^{(i)} + c\big)}{s\sqrt{a^2+b^2}} \\ &=\frac{t^{(i)} \cdot \big(ax_{1}^{(i)} + bx_{2}^{(i)} + c\big)}{\sqrt{a^2+b^2}} \end{aligned} \]
Vores betingelser er derfor uændrede, når vi skalerer \(a,b\) og \(c\). Det betyder, at hvis \(a,b,c\) er en løsning til vores problem, så er \(sa,sb,sc\) det også. For at undgå problemet med flere løsninger, vil vi fastlægge skaleringen således at \(a^2+b^2=1\). Så bliver nævneren i (3) \(\sqrt{a^2+b^2}=\sqrt{1}=1\). Vi kan derfor omformulere vores optimeringsproblem til:
Support Vector Machine i planen – optimeringsproblem
Find \(a,b,c\in \mathbb{R}\) og \(M>0\), der maksimerer \(M\) under betingelserne
\[ t^{(i)} \cdot \big(ax_{1}^{(i)} + bx_{2}^{(i)} + c\big)\geq M \tag{4}\]
og
\[ a^2+b^2=1 \tag{5}\]
Dette problem kan løses i Excel. Først og fremmest skal man sørge for, at man har aktiveret problemløser-værktøjet. Det gøres på følgende måde:
Gå op under filer og vælg indstillinger.
Vælg derefter tilføjelsesprogrammer.
Nederst vælges Excel-tilføjelsesprogrammer. Tryk på udfør.
Vælg til sidst tilføjelsesprogrammet problemløser fra en liste.
Videoen nedenfor viser nu, hvordan optimeringen foregår i Excel.
Problemer med algoritmen
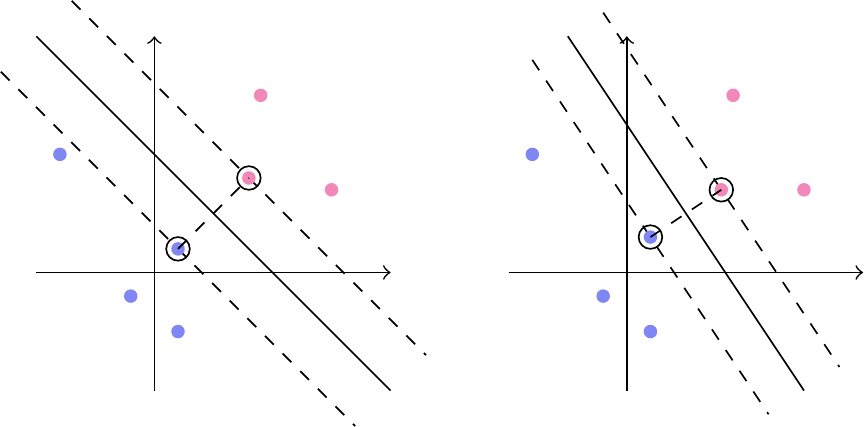
I praksis er linjens placering bestemt af de punkter, der ligger lige på kanten af linjens margin kaldet supportvektorerne. Flytter man bare en lille smule på supportvektorerne, kan det ændre meget på linjens placering, se figur 7. De øvrige punkter kan man godt flytte lidt, uden at det ændrer på linjen.
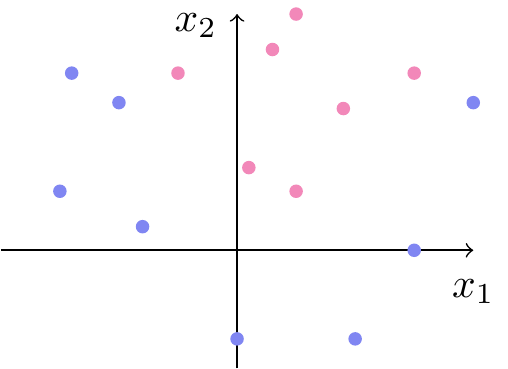
Indtil videre har vi antaget, at det er muligt at adskille klasserne med en linje. Det er dog langt fra altid muligt at finde sådan en linje, se for eksemplet datasættet på figur 8. Hvordan man kan løse det problem, ser vi nærmere på i næste afsnit.
Selv hvis linjen adskiller alle punkter i træningsdata korrekt, er det ikke sikkert, at et nyt punkt også vil komme til at ligge på den rigtige side. Det skyldes, at vi ikke havde set alt data i verden, da vi lavede linjen, men kun vores ret begrænsede træningsdata. Et nyt punkt, der ligger tæt på skillelinjen, vil typisk have høj risiko for fejlklassificering. Hvis et nyt punkt ligger langt fra linjen, vil prædiktionen være mere sikker, se figur 9.
Endelig er algoritmen baseret på afstande fra punkt til linje. Det betyder, at det ikke er lige meget, hvilke enheder variablene er målt i. Det kan du læse mere om i noten om Feature-skalering.
Skillelinje med blød margin
På figur 8 så vi et eksempel på et datasæt, hvor klasserne ikke kan adskilles af en linje. Vil man stadig gerne have en skillelinje, der adskiller klasserne bedst muligt, kan man tillade enkelte punkter at ligge lidt inden for margin — vi laver en blød margin. Det gør man ved for hvert punkt \(i\) at indføre en slækkevariabel \(\varepsilon_i\geq 0\), der måler, hvor meget vi slækker på kravet om, at punkterne skal ligge uden for en margin med bredde \(M\). Vi erstatter så kravet
\[ \frac{t^{(i)} \cdot \big(ax_{1}^{(i)} + bx_{2}^{(i)} + c\big)}{\sqrt{a^2+b^2}} \geq M \tag{6}\]
med
\[ \frac{t^{(i)} \cdot \big(ax_{1}^{(i)} + bx_{2}^{(i)} + c\big)}{\sqrt{a^2 + b^2}} \geq M(1-\varepsilon_i) \]
Vi har følgende fortolkning af slækkevariablene:
Hvis \(\varepsilon_i=0\), genfinder vi kravet (6) om, at punktet ligger på den rigtige side af linjen med afstand mindst \(M\) til linjen.
Hvis \(0<\varepsilon_i <1\), så er \(M(1-\varepsilon_i)\) positiv. Det betyder, at vi stadig kræver, at punktet ligger på den rigtige side af linjen, men afstanden til linjen er nu \(M(1-\varepsilon_i)<M\), så punktet ligger inden for margin.
Hvis \(\varepsilon_i>1\), så er \(M(1-\varepsilon_i)<0\). Her er \(t^{(i)} \cdot \big(ax_{1}^{(i)} + bx_{2}^{(i)} + c\big)<0\) svarende til, at punktet ligger på den forkerte side af linjen. Afstanden til linjen er \(|M(1-\varepsilon_i)|\).
Fortolkningen er illustreret på figur 10. Supportvektorerne er nu alle punkter, der ligger inden for eller på kanten af margin.
For at styre, hvor meget vi tillader punktene at overskride linjens margin, tilføjer vi en begrænsning på summen af slækkevariablene \[\varepsilon_1+\dotsm + \varepsilon_n \leq K\] Her er \(K\) en konstant, som vi vælger alt efter, hvor blød vi ønsker, at marginen skal være. Jo større \(K\) er, desto blødere margin. Hvis \(K\) vælges for lille, er det ikke sikkert, at det er muligt at finde en linje, der opfylder kravet. Hvis \(K\) vælges for stor, kan punkterne overskride marginen meget. I praksis er det svært at vide, hvordan \(K\) vælges bedst. Normalt vil man prøve sig frem med forskellige værdier og så bruge krydsvalidering til at vælge den bedste.
For at finde den optimale linje med blød margin, skal vi altså løse følgende optimeringsproblem med rigtig mange ubekendte variable.
Support Vector Machine i planen – optimeringsproblem med blød margin
Find \(a,b,c\in \mathbb{R}\), \(M>0\) og \(\varepsilon_1,\ldots,\varepsilon_n\geq 0\), der maksimerer \(M\) under betingelserne
\[ \frac{t^{(i)}\big(ax_{1}^{(i)} + bx_{2}^{(i)} + c\big)}{\sqrt{a^2+b^2}}\geq M(1-\varepsilon_i)\qquad \text{ for alle } i=1,\ldots,n \]
og
\[ \varepsilon_1+\dotsm + \varepsilon_n \leq K \]
Beregningerne kan i princippet laves som i tilfældet med hård margin, men der er rigtig mange ukendte variable, både \(a,b,c,M\) og alle \(\varepsilon_1,\ldots,\varepsilon_n\). Vi vil derfor ikke selv gøre det i Excel.
Support vector machines i tre dimensioner
Det kunne også være, at vi havde målt tre biomarkører \((x_1,x_2,x_3)\) for at få mere information at lave prædiktionerne ud fra. Vores målinger kan nu plottes som punkter i et tredimensionalt koordinatsystem. Igen farves punkterne lyserøde, hvis lægemidlet havde en effekt og blå ellers. Det kunne se ud som på figur 11.
Vi kan nu prøve at finde en plan i \(\mathbb{R}^3\), der adskiller punkterne. Som før søger vi den plan, der har størst mulig afstand til det nærmeste punkt. Denne afstand vil vi igen kalde \(M\). Den optimale plan i eksemplet figur 11 er vist på figur 12.
Husk på, at en plan \(\alpha\) i \(\mathbb{R}^3\) består af de punkter \((x_1,x_2,x_3)\in \mathbb{R}^3\), der opfylder ligningen
\[ ax_1+bx_2+cx_3 +d=0 \]
Som i to dimensioner kan man vise, at en plan inddeler \(\mathbb{R}^3\) i to halvrum, et hvor \(ax_1+bx_2+cx_3 +d>0\) og et hvor \(ax_1+bx_2+cx_3 +d<0\). Planens normalvektor \[ \vec{n}=\begin{pmatrix} a\\b\\c \end{pmatrix} \]
peger i den retning hvor \(ax_1+bx_2+cx_3 +d>0\). Desuden kan man vise, at afstanden fra et punkt \(P=(z_1,z_2,z_3)\) til planen er givet ved
\[ \textrm{dist}(P,\alpha) = \frac{|az_1+bz_2+cz_3 +d|}{\sqrt{a^2+b^2+c^2}} \]
Man kan derfor regne helt som i det todimensionale tilfælde og finde den plan, der adskiller klasserne med størst mulig afstand til det nærmeste punkt. Hvis man ønsker en hård margin, skal man løse optimeringsproblemet:
Support Vector Machine i rummet – optimeringsproblem med hård margin
Find \(a,b,c,d\in \mathbb{R}\) og \(M>0\), der maksimerer \(M\) under betingelserne
\[ {t^{(i)} \cdot \big(ax_{1}^{(i)} + bx_{2}^{(i)} +cx_{3}^{(i)} + d \big)}\geq M\qquad \text{ for alle } i=1,\ldots,n \tag{7}\]
og
\[ a^2+b^2+c^2=1 \tag{8}\]
Ikke-lineære support vector machines
Det er ikke altid, at en ret linje er det bedste til at adskille to klasser. På figur 13 er vist et eksempel, hvor det ville give mere mening at adskille klasserne med en blød kurve.
Hvis man ønsker en ikke-lineær adskillelse af klasserne, kan man indlejre punkterne i et højeredimensionalt rum og håbe på, at de bliver nemmere at adskille der. Betragt for eksempel funktionen af to variable
\[ f(x_1,x_2)=x_1^2 \]
Vi kan bruge den til at indlejre det todimensionale punkt \((x_1,x_2)\) i et tredimensionalt koordinatsystem som punktet
\[ (x_1,x_2,f(x_1,x_2))=(x_1,x_2,x_1^2) \]
på grafen for \(f\). Det er vist på figur 14.
Vi kan nu prøve at finde en plan i \(\mathbb{R}^3\), der adskiller punkterne. I vores eksempel kunne punkterne ikke adskilles af en linje i to dimensioner, men som det ses på figur 15, er det muligt at finde en plan, der adskiller punkterne helt i tre dimensioner (prøv at rotere figuren for at se den lyserøde klasse).
Lad os sige, at vi har fundet planen \(ax_1+bx_2+cx_3+d=0\). Da vores punkter er på formen \((x_1,x_2,x_3)=(x_1,x_2,x_1^2)\), klassificerer vi dem efter fortegnet på
\[ ax_1+bx_2+cx_3+d=ax_1 + bx_2 + cx_1^2 +d \]
Skellet mellem klasserne bliver de punkter, hvor
\[ ax_1 + bx_2 + cx_1^2 +d=0 \]
Hvis \(b\neq 0\), kan vi isolere \(x_2\) og få
\[ x_2 = -\frac{c}{b}x_1^2 -\frac{a}{b}x_1 - \frac{d}{b} \]
Vi genkender dette som ligningen for en parabel. Hvis \(ax_1 + bx_2 + cx_1^2 +d>0\) og \(b>0\) får vi tilsvarende, at
\[ x_2 > -\frac{c}{b}x_1^2 -\frac{a}{b}x_1 - \frac{d}{b} \]
Det svarer til punkter, der ligger over parablen. Vi ser altså, at klasse \(1\) skal ligge over parablen. Tilsvarende skal klasse \(-1\) ligge under. Hvis \(b<0\) er det omvendt.
Hvis vi i dataeksemplet fra figur 13 indlejrer punkterne i \(\mathbb{R}^3\) og adskiller dem med en plan, som vist på figur 14 og figur 15, så svarer det altså til, at vi adskiller de oprindelige punkter i \(\mathbb{R}^2\) med en parabel som vist på figur 16.
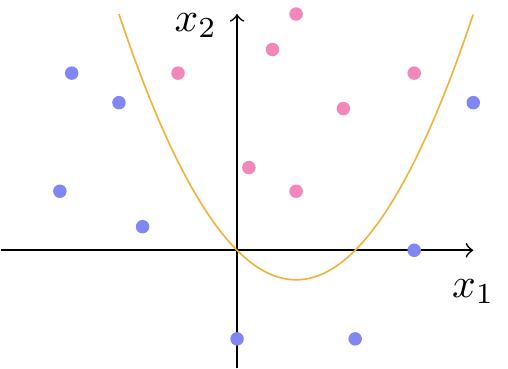
Der er mange måder at vælge funktionen \(f\), der indlejrer punkterne i \(\mathbb{R}^3\). Det er muligt at opnå kurver, der bugter sig meget efter datapunkterne. Det indebærer desværre en risiko for overfitting, hvor algoritmen kommer til at tilpasse sig for godt til lige præcis de datapunkter, der var med i vores træningsdatasæt, men ikke nødvendigvis egner sig til at forudsige nyt data. Derfor bør man bruge krydsvalidering til at hjælpe med at vælge en god model. Det kan du læse mere om her.