Simple kunstige neurale netværk til regression
Hvis du har læst nogle af vores andre noter om kunstige neurale netværk, så har de alle handlet om klassifikation. Det kunne for eksempel være: aktiverer en kunde et tilbud i en app? (ja/nej), bliver det regnvejr i morgen? (ja/nej), har en patient en bestemt sygdom? (ja/nej), hvilket af fire valg skal jeg træffe? De tre første eksempler er eksempler på det, som man kalder for binær klassifikation (fordi der kun er to muligheder), mens det sidste eksempel er et eksempel på multipel klassifikation (fordi der er mere end to muligheder). I denne note vil vi se på, hvordan man kan bruge kunstige neurale netværk til at forudsige en såkaldt numerisk variabel – mere konkret vil vi her se på, hvordan man kan lave et kunstigt neuralt netværk, som kan bruges til at prædiktere salgsprisen på en lejlighed i Aalborg.
Hvad koster min lejlighed?
Vi forestiller os helt generelt en række inputvariable eller features: \(x_1, x_2, \dots, x_n\) på baggrund af hvilke vi gerne vil kunne forudsige en såkaldt targetvariabel \(t\), som her er salgsprisen på en lejlighed i Aalborg.
Eksempel 1 (Lejlighedspriser – Home datasættet) 
Ejendomsmæglerkæden "Home" har stillet information om salg af ejendomme i perioden fra 2010 til 2022 til rådighed. Vi har i dette eksempel valgt at se på salget af lejligheder beliggende i 9000 Aalborg. Du kan downloade denne del af datasættet her.
Targetvariablen \(t\) står i kolonnen pris og angiver salgsprisen af en given lejlighed. Derudover indeholder det oprindelige datasættet en lang række oplysninger, men vi har her valgt kun at fokusere på en delmængde af disse.
Vi vil specielt se på følgende features:
areal: boligens areal målt i kvadratmeter (\(x_1\))alder: boligens alder i år (\(x_2\))
Og vi vil lade targetvariablen \(t\) være
- \(t\): boligens pris i kroner
I eksemplet her har vi information om \(1136\) salg af lejligheder. Dette datasæt kaldes for træningsdata.
Vi vil starte simpelt og opstille det, som man kalder for en kunstig neuron til formålet. Så vil vi sige, at vores prædiktion af salgsprisen skal være en outputværdi \(o\), som helt generelt er den vægtede sum af vores inputvariable:
\[ o = w_0 + w_1 \cdot x_1 + w_2 \cdot x_2 + \cdots + w_n \cdot x_n \]
Her kaldes \(w_0, w_1, w_2, \dots, w_n\) for vægte.
Hvis du har læst noten om kunstige neuroner, så er den eneste forskel her, at vi ikke længere bruger sigmoid-funktionen som aktiveringsfunktion1, fordi vi ikke her har brug for at få en outputværdi, som ligger mellem \(0\) og \(1\).
1 Vi bruger sådan set stadig en aktiveringsfunktion – det bare den funktion, som kaldes for identiteten med forskrift \(f(x)=x\).
Vi ønsker, at bestemme vægtene \(w_0, w_1, w_2, \dots, w_n\) sådan at vores prædikterede salgspris \(o\) kommer så tæt som muligt på den faktiske salgspris \(t.\)
Det vil sige, at vi ønsker, at forskellen
\[ t-o = t - \left ( w_0 + w_1 \cdot x_1 + w_2 \cdot x_2 + \cdots + w_n \cdot x_n \right ) \]
bliver så lille som mulig.
Da denne differens både kan være positiv og negativ, men vi egentlig ikke er interesseret i fortegnet – blot om differensen er lille eller stor, så vælger vi i stedet at se på den kvadrerede forskel:
\[ \left ( t - \left ( w_0 + w_1 \cdot x_1 + w_2 \cdot x_2 + \cdots + w_n \cdot x_n \right ) \right )^2 \]
Vi får en sådan kvadreret differens for hvert eneste salg i vores træningsdatasæt, og vi vælger derfor blot at lægge alle disse størrelser sammen:
\[ E = \frac{1}{2}\sum \left ( t - \left ( w_0 + w_1 \cdot x_1 + w_2 \cdot x_2 + \cdots + w_n \cdot x_n \right ) \right )^2 \]
Størrelsen \(E\) kaldes for en tabsfunktion. Læg mærke til, at hvis vores kunstige neuron er god til at forudsige salgspriser, så får vi en lille værdi af tabsfunktionen, mens vi får en stor værdi af \(E\), hvis den kunstige neuron er dårlig til at forudsige salgspriser. Vi har her valgt at gange med \(\frac{1}{2}\), fordi det senere kommer til at forkorte ud, men det er faktisk ikke så afgørende.
Idéen er så bare at bestemme værdier af vægtene \(w_0, w_1, w_2, \dots, w_n\) sådan, at tabsfunktionen minimeres.
Inden vi forklarer, hvordan det gøres, så lad os blive lidt mere specifikke i forhold til notationen af vores træningsdata. Vi forestiller os, at vi har information om \(M\) lejlighedssalg (i eksemplet er \(M=1136\)). Så vil vi nummere vores træningsdata på denne måde:
\[ \begin{aligned} &\text{Træningseksempel 1:} \quad (x_1^{(1)}, x_2^{(1)}, \dots, x_n^{(1)}, t^{(1)}) \\ & \quad \quad \quad \quad \vdots \\ &\text{Træningseksempel m:} \quad (x_1^{(m)}, x_2^{(m)}, \dots, x_n^{(m)}, t^{(m)}) \\ & \quad \quad \quad \quad \vdots \\ &\text{Træningseksempel M:} \quad (x_1^{(M)}, x_2^{(M)}, \dots, x_n^{(M)}, t^{(M)}) \\ \end{aligned} \]
Gør vi det, bliver tabsfunktionen:
\[ \begin{aligned} E(w_0, w_1, &\dots, w_n) \\ &= \frac{1}{2} \sum_{m=1}^{M} \left (t^{(m)}- (w_0 + w_1 \cdot x_1^{(m)} + \cdots + w_n \cdot x_n^{(m)}) \right)^2. \end{aligned} \]
Hvis vi samtidig indfører, at vi kalder outputværdien for det \(m\)’te lejlighedssalg for \(o^{(m)}\):
\[ o^{(m)} = w_0 + w_1 \cdot x_1^{(m)} + \cdots + w_n \cdot x_n^{(m)} \] Så kan tabsfunktionen udtrykkes kort på denne måde:
\[ \begin{aligned} E(w_0, w_1, &\dots, w_n) \\ &= \frac{1}{2} \sum_{m=1}^{M} \left (t^{(m)}- o^{(m)} \right)^2 \end{aligned} \tag{1}\]
hvor det nu så bare ikke er helt så tydeligt, at \(E\) jo faktisk afhænger af alle vægtene.
For at bestemme de værdier af vægtene, som minimerer tabsfunktionen, vil vi bruge en metode, som kaldes for gradientnedstigning. Vi har lavet videoer om både funktioner af to variable og gradientnedstigning, hvis du vil vide mere. Du kan også læse i noterne om funktioner af flere variable og gradientnedstigning.
Idéen i gradientnedstigning er, at vi starter med at vælge nogle tilfældige værdier af vægtene, som vi kalder \(w_0, w_1, \dots, w_n\). For de valgte værdier af vægtene kan vi udregne gradienten, som er vektoren bestående af alle de partielle afledede \(\frac{\partial E }{\partial w_0}\), \(\frac{\partial E }{\partial w_1}, \dots, \frac{\partial E }{\partial w_n}\). Man kan vise, at denne gradient peger i den retning, hvor funktionsværdien vokser mest. Det kommer omvendt til at betyde, at den negative gradient peger i den retning, hvor funktionsværdien falder mest. Vi opdaterer derfor alle vægtene til \(w_0^{(\textrm{ny})}, w_1^{(\textrm{ny})}, \dots, w_n^{(\textrm{ny})}\) ved at gå et lille stykke i den negative gradients retning. Vi vælger, at skrive det sådan her:
\[ \begin{aligned} w_0^{(\textrm{ny})} \leftarrow & w_0 - \eta \cdot \frac{\partial E }{\partial w_0} \\ w_1^{(\textrm{ny})} \leftarrow & w_1 - \eta \cdot \frac{\partial E }{\partial w_1} \\ &\vdots \\ w_n^{(\textrm{ny})} \leftarrow & w_n - \eta \cdot \frac{\partial E }{\partial w_n} \\ \end{aligned} \]
hvor \(\eta\) kaldes for en learning rate. Vi gentager nu processen. Med udgangspunkt i de nye vægte beregner vi de partielle afledede med de nye vægte og opdaterer vægtene igen. Sådan fortsættes indtil vi nærmer os et minimumspunkt.
Vi får derfor brug for alle de partielle afledede af \(E\) med hensyn til \(w_i\) for \(i \in \{0, 1, 2, \dots, n\}\). Man kan vise, at
\[ \begin{aligned} \frac{\partial E}{\partial w_i} &= - \sum_{m=1}^M \left (t^{(m)}- (w_0 + w_1 \cdot x_1^{(m)} + \cdots + w_n \cdot x_n^{(m)}) \right) \cdot x_i^{(m)} \\ &= - \sum_{m=1}^M \left (t^{(m)}- o^{(m)} \right) \cdot x_i^{(m)} \end{aligned} \] for \(i \in \{1, 2, \dots, n\}\) og
\[ \frac{\partial E}{\partial w_0} = - \sum_{m=1}^M \left (t^{(m)}- o^{(m)} \right) \] Opdateringsreglerne for vægtene bliver derfor:
At opstille en kunstig neuron til regression, som vi har gjort her, svarer til det, man kalder for multipel lineær regression, som egentlig bare er en udvidelse af lineær regression, som I kender det, blot med flere inputvariable/features.
Det gode ved at opstille en kunstig neuron til regression, som vi her har gjort det, er, at man kan give en fortolkning af vægtene.
Fortolkning af vægtene
Lad os sige, at vi har bestemt vægtene \(w_0, w_1, \dots, w_n\), så tabsfunktionen er blevet minimeret, og at \(x_1\) fortsat angiver boligarealet. Vi vil her forklare, hvordan vi kan fortolke \(w_1\).
Vi forstiller os, at vi har to lejligheder med præcis samme værdier af de \(n\) features \(x_1, x_2, \dots, x_n\) bortset fra, at den ene lejlighed er præcis \(1 \, m^2\) større end den anden. Så den ene lejlighed har en størrelse på \(x_1 \, m^2\), mens den anden har en størrelse på \(x_1+1 \, m^2\) – de resterende features er ens.
Det giver følgende prædikterede salgspriser \(o_1\) og \(o_2\) for de to lejligheder:
\[ \begin{aligned} o_1 &= w_0 + w_1 \cdot x_1 + w_2 \cdot x_2 + \cdots + w_n \cdot x_n \\ \\ o_2 &= w_0 + w_1 \cdot (x_1 + 1) + w_2 \cdot x_2 + \cdots + w_n \cdot x_n \\ &= w_0 + w_1 \cdot x_1 + w_1 + w_2 \cdot x_2 + \cdots + w_n \cdot x_n \end{aligned} \]
Da bliver forskellen mellem de to prædikterede salgspriser:
\[ \begin{aligned} o_2 - o_1 &= w_0 + w_1 \cdot x_1 + w_1 + w_2 \cdot x_2 + \cdots + w_n \cdot x_n \\ & \quad \quad - \left ( w_0 + w_1 \cdot x_1 + w_2 \cdot x_2 + \cdots + w_n \cdot x_n \right) \\ &= w_0 + w_1 \cdot x_1 + w_1 + w_2 \cdot x_2 + \cdots + w_n \cdot x_n \\ & \quad \quad - w_0 - w_1 \cdot x_1 - w_2 \cdot x_2 - \cdots - w_n \cdot x_n \\ & = w_1 \end{aligned} \]
Det vil sige, at hvis alt andet er holdt ens, så vil en forøgelse i boligarealet på \(1 \, m^2\) give en forøgelse i den prædikterede salgspris på \(w_1\) kroner.
Da \(x_2\) angiver lejlighedens alder, så vil \(w_2\) helt tilsvarende kunne fortolkes som den størrelse, den prædikterede salgspris vil ændres med, hvis en lejlighed er præcis ét år ældre end en anden tilsvarende lejlighed (det vil her sige en lejlighed med samme areal).
Vi illustrerer dette med et eksempel:
Eksempel 2 (Lejlighedspriser – fortolkning af vægtene) Man kan træne en kunstig neuron til regression ved at bruge Kunstig neuron til regression app.
Bruger vi denne app på datasættet om lejlighedssalg, hvor vi sætter alle startvægte til \(0\), vælger en learning rate på \(0.001\) og antal iterationer til \(1000\), får vi følgende værdier af vægtene:
| \(w_0\) |
\(w_1\) ( areal) |
\(w_2\) ( alder) |
|---|---|---|
| \(0.06375\) | \(0.01951\) | \(-0.002349\) |
For eksempel kan vi se, at \(w_1 = 0.01951\). Det vil sige, at ifølge modellen vil prisen på en lejlighed, som er præcis én kvadratmeter større end en anden tilsvarende2 lejlighed, være cirka \(19510\) kroner højere (husk på, at prisen er målt i millioner, så vi skal lige gange med en million, hvis vi skal have værdien oversat til kroner). Det viser også, at modellen er meget simpel. Det er for eksempel ikke sikkert i virkelighedens verden, at en ekstra kvadratmeter har samme effekt på prisen for nye såvel som for gamle lejligheder.
2 En tilsvarende lejlighed vil her mere præcist betyde en lejlighed med den samme alder.
Vi ser også, at \(w_2=-0.002349\), som betyder, at hvis vi står med to lige store lejligheder, hvor den ene er præcis et år ældre end den anden, så vil salgsprisen på den ældste lejlighed ifølge modellen være \(2349\) kroner lavere.
I det nedenstående har vi plottet den faktiske pris (i millioner) ud af \(x\)-aksen og den prædikterede pris op af \(y\)-aksen.
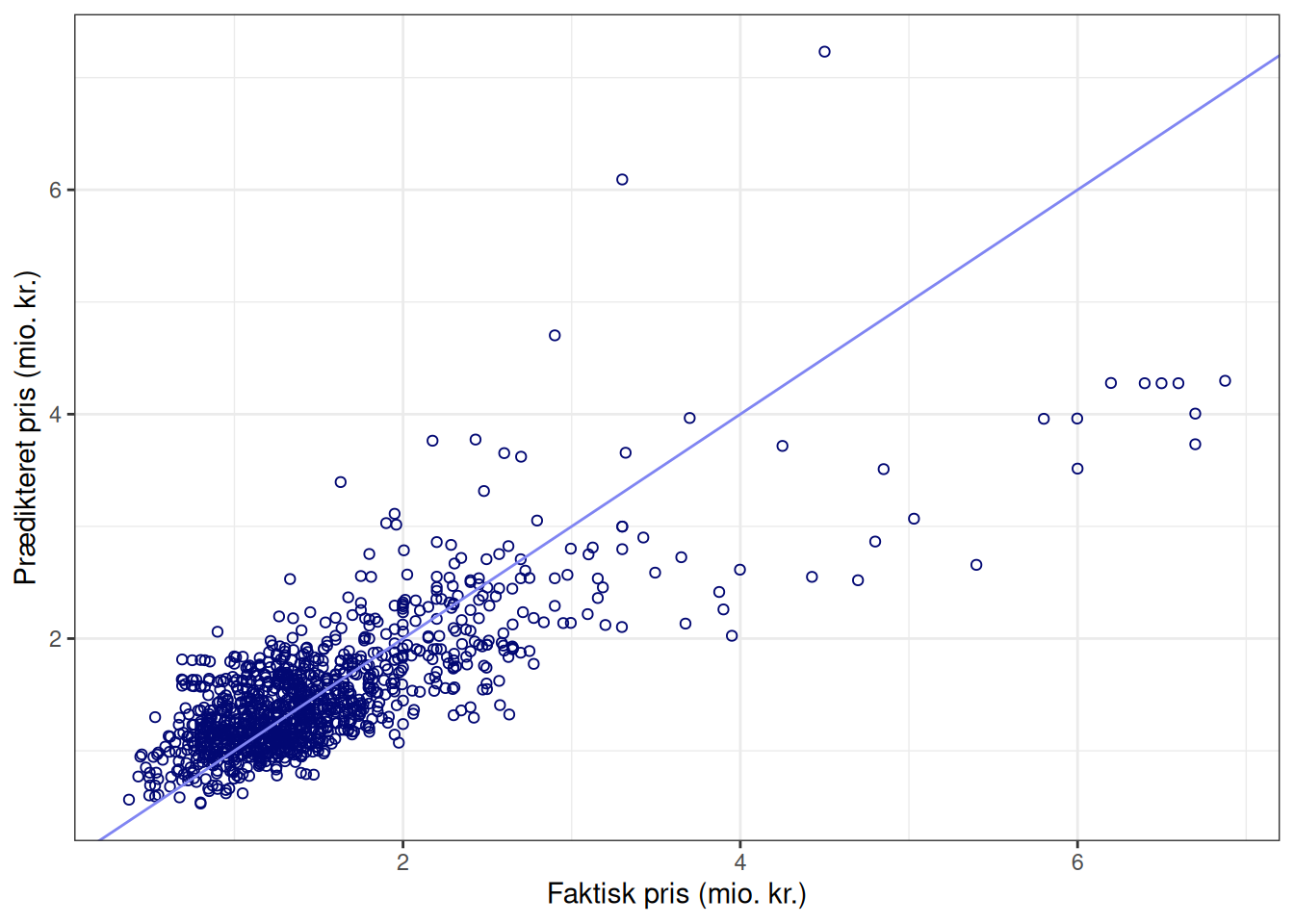
Hvis vi har en perfekt model, så vil den prædikterede pris være lig med den faktiske pris. Det vil svare til, at alle punkterne i figur 1 vil ligge på linjen med ligning \(y=x\) (som er indtegnet med lyseblå i figuren). På figuren kan vi derfor se, at for lejligheder, som koster under \(3\) millioner er modellen ikke helt dårlig. Det kunne dog godt se ud som om, at modellen prædikterer en for høj salgspris for de helt billige lejligheder (det ses ved, at der for de billige lejligheder er flere punkter i figuren, som ligger over linjen, end der ligger under). Til gengæld er modellen ikke super god til at prædiktere salgsprisen for de dyrere lejligheder: For nogle lejligheder er den prædikterede salgspris for høj, mens det omvendte også gør sig gældende – specielt de meget dyre lejligheder, som koster over \(5\) millioner, prædikterer modellen for lavt. Der er altså noget her, som tyder på, at vores model er lidt for simpel.
Vurdering af modellens anvendelighed
Når man træner en kunstig neuron, har man brug for et mål for, hvor god modellen er. Det bliver for eksempel vigtigt, når vi senere gerne vil sammenligne flere forskellige modeller.
Du kender nok allerede \(R^2\)-værdien fra lineær regression, som et tal mellem \(0\) og \(1\), hvor vi gerne vil have tallet så tæt på \(1\) som muligt3. Hvis du vil vide mere om, hvordan \(R^2\)-værdien rent faktisk regnes ud, kan du læse mere her.
3 Og så alligevel ikke helt – det kommer vi tilbage til senere.
Et andet mål, som kan bruges til at sammenligne modeller, er root mean squared error (RMSE). Du kan læse en lidt længere forklaring her, men målet er defineret således:
\[ \mathrm{RMSE} = \sqrt{\frac{1}{M} \sum_{m=1}^{M} \left (t^{(m)}-o^{(m)} \right)^2} \]
Da vi ønsker så lille en fejl (\(t^{(m)}-o^{(m)}\)) som muligt, vil vi gerne have, at RMSE er så tæt på \(0\) som muligt.
Eksempel 3 (Lejlighedspriser – RMSE og \(R^2\)) Ser vi på den kunstige neuron fra eksempel 2 kan man udregne RMSE. Gør man det får man
\[ \mathrm{RMSE} = 0.4972 \]
Uden sammenligning med andre modeller er det svært at vide, om det tal er godt eller skidt. Til gengæld kan vi udregne \(R^2\)-værdien, som er
\[ R^2 = 0.5962 \] Du er måske vant til at se \(R^2\)-værdier, som er meget større, men for en model baseret på et datasæt fra den virkelige verden, er det såmen ikke helt tosset! Det skyldes, at der altid vil være ting, som man ikke kan forklare, når man som her vil prædiktere huspriser. Det er for eksempel svært at sætte tal på udsigten, hvor fint lejligheden er renoveret, hvor meget naboerne larmer og så videre. Til sammenligning har vi som regel målt alle de forskellige faktorer, som påvirker et forsøg i fysik, og her vil vi typisk se \(R^2\)-værdier, som er meget højere.
Krydsvalidering
Når en models anvendelighed vurderes ved hjælp af mål som RMSE og \(R^2\)-værdi, så vil det altid være sådan, at jo mere kompliceret en model, man bruger, desto bedre mål vil man få (det vil sige en lille værdi af RMSE og en værdi af \(R^2\), som er tæt på \(1\)). Hvorfor det er tilfældet, kan du læse meget mere om i noten Overfitting, modeludvælgelse og krydsvalidering). Men kort fortalt går det ud på, at en meget kompliceret model kan fange tendenser i data, som i virkeligheden ikke er reelle – det er bare støj. Et eksempel ses i figur 2. Her er ti punkter indtegnet, hvor der er anvendt lineær regression (den lyseblå linje) og 9. grads polynomiel regression (den lyserøde kurve).
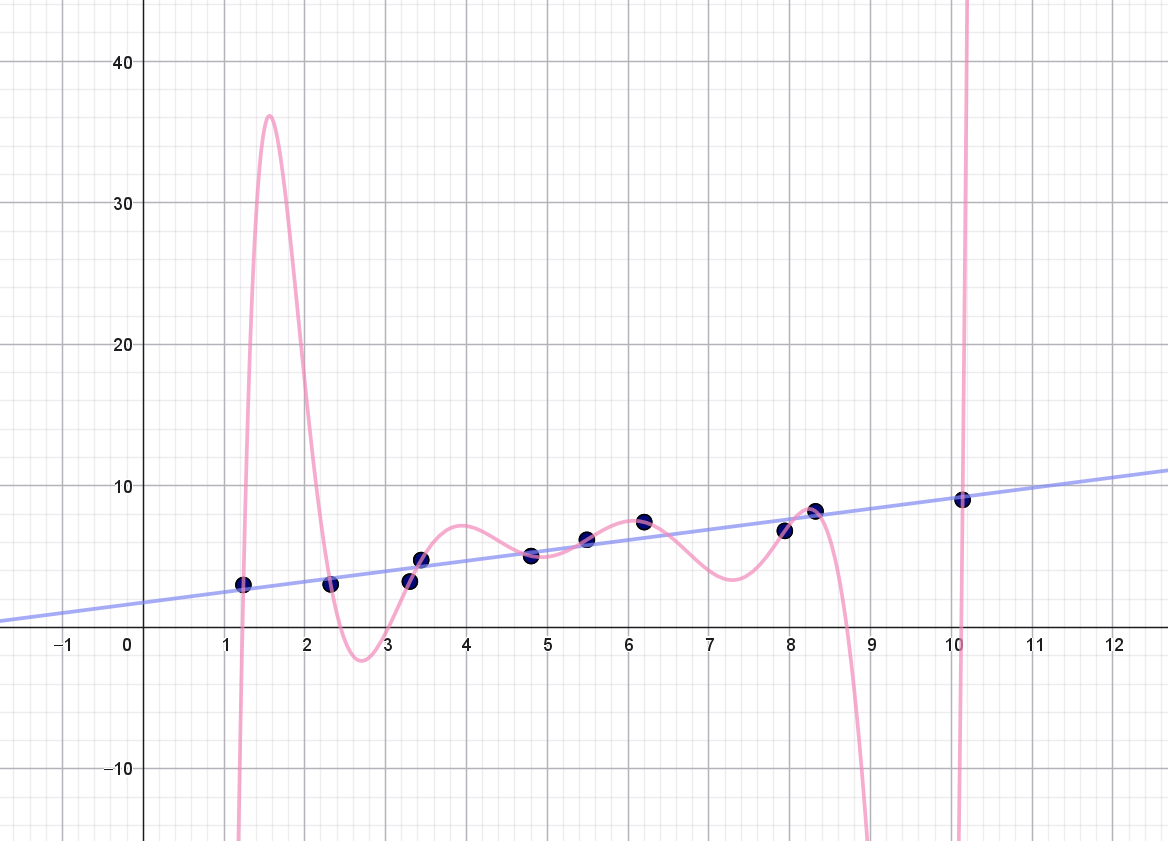
Det kan her ses, at en ret linje beskriver punkterne udmærket. Et 9. grads polynomium har til gengæld så meget fleksibilitet, at grafen for polynomiet kan gå igennem alle ti punkter. Det ses tydeligt på figur 2, at det bliver alt for mærkeligt, og vi har ingen forventninger om, at dette polynomium vil kunne bruges til at beskrive nye punkter, som ikke kommer fra datasættet. Men bruger vi for eksempel \(R^2\)-værdien til at sammenligne de to modeller, så får vi:
| Model | \(R^2\)-værdi | RMSE |
|---|---|---|
| Lineær regression | \(0.916\) | \(0.603\) |
| 9. grads polynomiel regression | \(1.000\) | \(0.000\) |
Så ser vi alene på \(R^2\)-værdien og RMSE, kunne vi blive foranlediget til at tro, at vi skulle vælge polynomiel regression. Man skal altså være utrolig varsom med uden videre at sammenligne den type af mål! Men hvad gør man så? Ét bud er at bruge noget, som kaldes for krydsvalidering. Princippet er illustreret i figur 3.
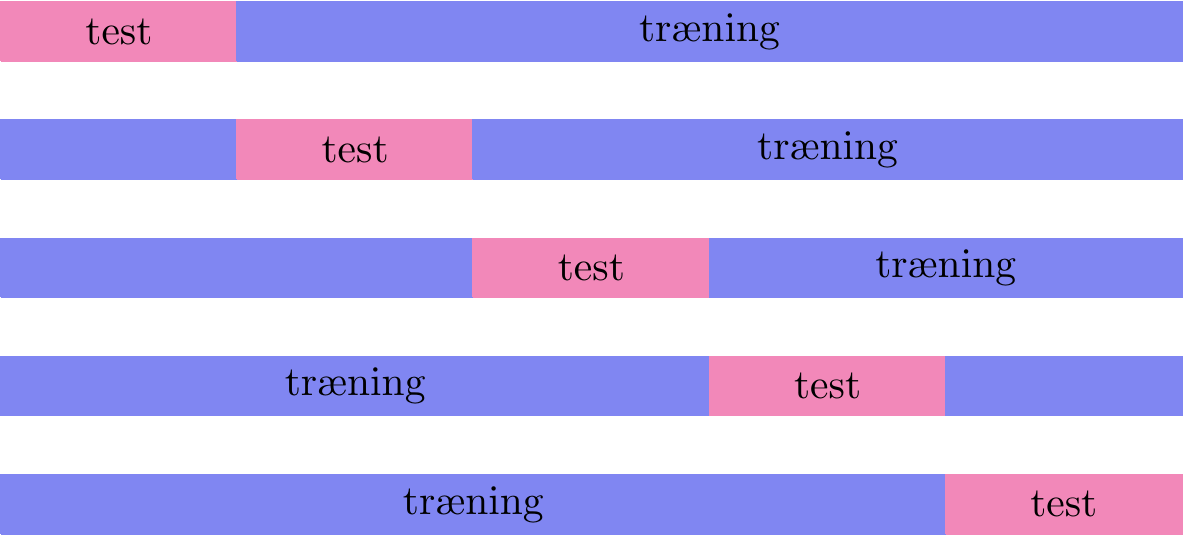
Man starter med at inddele data tilfældigt i \(5\) lige store dele: del 1, 2, 3, 4 og 5. Så træner man en model (lad os sige, at man laver lineær regression) baseret på del 2, 3, 4 og 5. Det giver en ret linje. Hefter bruger man del 1 til at udregne for eksempel RMSE baseret på den model, man lige har bestemt.
Har man for eksempel et datasæt med \(500\) dataeksempler så udregnes RMSE på denne måde:
\[ \mathrm{RMSE} = \sqrt{\frac{1}{100} \sum_{m \in \textrm{del 1}}\left (t^{(m)}-o^{(m)} \right)^2} \]
Her summerer vi altså over alle \(100\) træningseksempler i del 1. Husk på, at outputværdien \(o^{(m)}\) findes ved
\[ o^{(m)} = w_0 + w_1 \cdot x_1^{(m)} + \cdots + w_n \cdot x_n^{(m)} \]
Her stammer inputværdierne \(x_1^{(m)}, x_2^{(m)}, \dots, x_n^{(m)}\) fra del 1, men vægtene \(w_0, w_1, w_2, \dots, w_n\) er fundet ved at bruge data fra del 2, 3, 4 og 5. Man undersøger altså, hvor god modellen er til at prædiktere data i del 1, hvis den kun er trænet på data fra del 2, 3, 4 og 5. Derfor kalder man del 1 for testdata og del 2, 3, 4 og 5 for træningsdata. Det er helt essentielt her, at man tester sin model på en del af data, som ikke har været brugt til at træne modellen på. Dette gentager man så, men næste gang er det del 2, som er testdata, og del 1, 3, 4 og 5, som er træningsdata. Igen udregnes RMSE. Denne proceduren gentages i alt 5 gang. Det giver 5 forskellige RMSE værdier. Herefter tager man gennemsnittet af dem for at få et samlet mål for modellens anvendelighed.
Det viser sig, at det ikke giver så meget mening, at udregne \(R^2\)-værdien i forbindelse med krydsvalidering. For eksempel kan værdien gå hen og blive negativ. Vi vil derfor i det følgende nøjes med at se på RMSE.
Eksempel 4 (Lejlighedspriser – RMSE med krydsvalidering) Vi vil nu udregne RMSE baseret på \(5\)-folds krydsvalidering. Det giver
\[ \mathrm{RMSE} = 0.499 \]
Bemærk, at hvis vi sammenligner med RMSE, som ikke er baseret på krydsvalidering fra eksempel 3, så er RMSE blevet en smule højere her. Det er helt forventeligt, at modellen vil klare sig bedre, når den er testet på de data, som den også er trænet på.
Du kan lære mere om risikoen for overfitting i forløbet om Overfitting og krydsvalidering med polynomiel regression.
Prædiktion af lejlighedspriser – med skjulte lag!
Når man skal sælge en lejlighed, skal der helst ikke være skjulte fejl og mangler. Det kan til gengæld være en rigtig god idé med nogle skjulte lag, når man skal prædiktere lejlighedspriser! Det vil vi se på nu.
I det ovenstående kommer den prædikterede pris til at afhænge lineært af inputvariablene. Men verden er sjældent lineær – og en af styrkerne ved kunstige neurale netværk er netop, at de kan prædiktere størrelser eller kategorier ved hjælp af funktioner, som ikke er lineære. Vi skal derfor nu opstille et simpelt kunstigt neuralt netværk til prædiktion af lejlighedspriser. Vi vil lave et netværk med to features \(x_1, x_2\) men nu med noget, som vi vil kalde for et skjult lag, som her består af et antal neuroner. Det kan illustreres, som vist i figur 4:

Som det ses i figur 4, er der til hver pil knyttet en vægt (for eksempel \(v_1, u_1, w_1\) og så videre), som skal bruges til at udregne outputværdien \(o\). Hvis vi for en stund forestiller os, at vi kender alle vægtene, så udregner vi outputværdien \(o\) på følgende måde:
Ved hjælp af inputvariablene og \(v\)-vægtene (de lysegrønne pile på figur 4) beregner vi \(z_1\):
\[ z_1 = f(v_0 + v_1 \cdot x_1 + v_2 \cdot x_2) \] som selvfølgelig kan generaliseres til
\[ z_1 = f(v_0 + v_1 \cdot x_1 + \cdots + v_n \cdot x_n) \]
Her er \(f\) en funktion, som kaldes for en aktiveringsfunktion, og det er den, der gør, at vi ender med at prædiktere lejlighedspriser på en ikke-lineær måde. Den kommer vi tilbage til om lidt.
På tilsvarende vis udregner vi \(z_2\) ved at bruge \(u\)-vægtene (de mørkegrønne pile på figur 4):
\[ z_2 = f(u_0 + u_1 \cdot x_1 + u_2 \cdot x_2) \]
Når vi nu har \(z_1\) og \(z_2\) beregnes outputværdien \(o\), som vi gjorde det tidligere (her er \(w\)-vægtene vist som de lyseblå pile på figur 4):
\[ o = w_0 + w_1 \cdot z_1 + w_2 \cdot z_2 \]
ReLU aktiveringsfunktionen
Lad os se nærmere på aktiveringsfunktionen \(f\). Hvis du har læst nogle af vores andre noter, ved du, at en ofte anvendt aktiveringsfunktion er sigmoid-funktionen med forskrift:
\[ \sigma (x) = \frac{1}{1+\mathrm{e}^{-x}} \] Grafen for sigmoid-funktionen ses i figur 5.
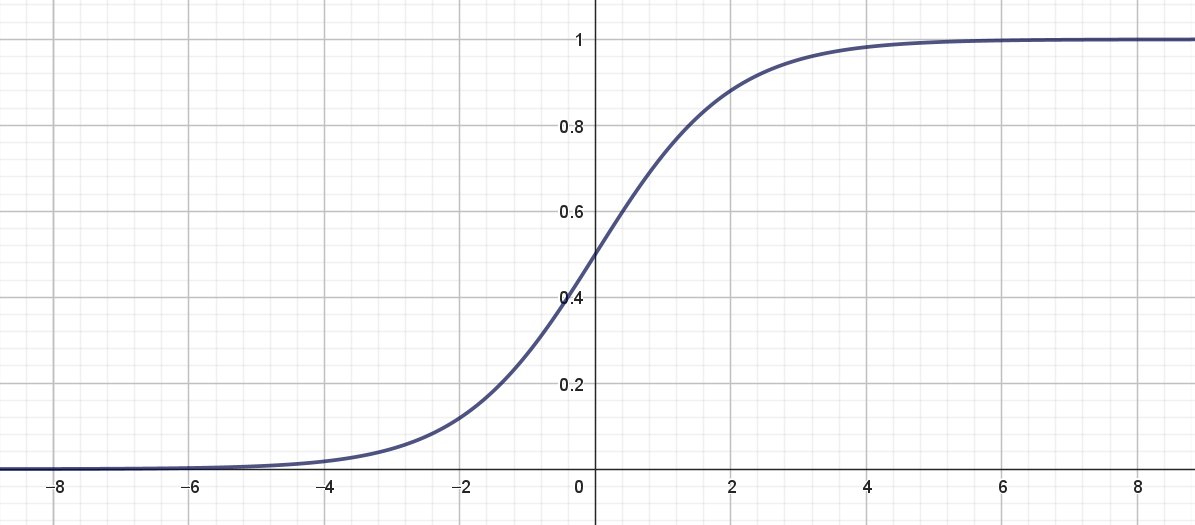
Denne aktiveringsfunktion er super god at bruge, når outputværdien skal beregnes, hvis man skal lave binær klassifikation, fordi funktionsværdien ligger mellem \(0\) og \(1\) og derfor kan fortolkes som en sandsynlighed. I alle andre sammenhænge er den faktisk ikke super anvendelig4!
4 Omvendt har Sigmoid-funktionen den (for en matematiker) fantastiske egenskab, at den er differentiabel, og man kan vise, at \(\sigma'(x) = \sigma(x) (1-\sigma(x))\).
5 ReLU står for Rectified Linear Unit.
En aktiveringsfunktion, som til gengæld ofte anvendes i de skjulte lag, er ReLU-funktionen5. Den er defineret således:
\[ \textrm{ReLU}(x) = \begin{cases} 0 & \textrm {hvis } x \leq 0 \\ x & \textrm {hvis } x > 0 \end{cases} \]
Grafen for ReLU-funktionen ses i figur 6.
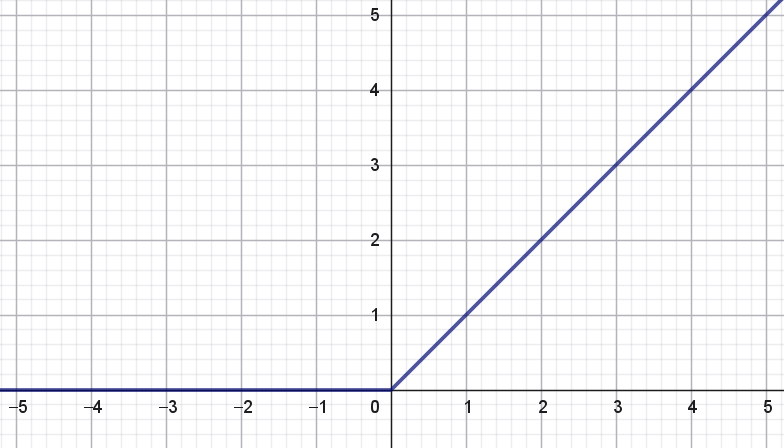
ReLU-funktionen transformerer altså alle negative inputværdier til \(0\) og alle positive inputværdier forbliver uændret. Det ser jo næsten lineært ud, men det er altså nok til, at man kan modellere nogle meget ikke-lineære funktioner, hvis bare man har nok skjulte lag med mange neuroner i hvert lag.
Nu er det sådan, at ReLU-funktionen faktisk ikke er differentiabel i \(x=0\) – til forskel fra Sigmoid-funktionen, som er differentiabel overalt. Til gengæld er det ikke svært at overbevise sig selv om, at
\[ \textrm{ReLU}'(x) = \begin{cases} 0 & \textrm{hvis } x < 0 \\ 1 & \textrm{hvis } x > 0 \end{cases} \]
Det ses nemt, ved at se på tangenthældningerne i figur 6. Og så definerer vi os simpelthen ud af tilfældet, hvor \(x=0\), og siger, at i \(0\) skal differentialkvotienten også være \(0\):
\[ \textrm{ReLU}'(0) = 0. \]
Feedforward udtryk
Ovenstående udtryk for beregning af \(z_1\), \(z_2\) og \(o\), hvor \(f\) nu beregner ReLU-funktionen, kaldes for feedforward ligninger, fordi man laver beregninger "fremad" i netværket i figur 4 fra venstre mod højre. Hvis vi samtidig holder styr på, hvilket træningseksempel vi står med, får vi følgende:
Tabsfunktionen definerer vi nu som før
\[ \begin{aligned} E(v_0, v_1, \dots, v_4, & u_0, u_1, \dots, u_4,w_0, w_1, w_2) \\ &= \frac{1}{2} \sum_{m=1}^{M} \left (t^{(m)}- o^{(m)} \right)^2 \end{aligned} \]
hvor \(o^{(m)}\) er givet ved udtrykket i (4). Læg mærke til, at tabsfunktionen afhænger af alle \(u\)-, \(v\)- og \(w\)-vægte, men for nemheds skyld vil vi blot skrive \(E\) i det følgende.
Hvis du ikke er interesseret i, hvordan man bestemmer vægtene, så spring det næste afsnit over og gå direkte videre til afsnittet Lejlighedspriser med neuralt netværk.
Backpropagation
Man kan nu igen bruge gradientnedstigning til at bestemme de værdier er \(v\)-, \(u\)- og \(w\)-vægtene, som minimerer tabsfunktionen. Det er her en vigtig beregningsfinte, at man bevæger sig "bagud" i netværket i figur 4 og først opdaterer \(w\)-vægtene (som er tættest på outputlaget) og dernæst \(u\)- og \(v\)-vægtene, som er tættest på inputlaget. Dette kaldes for backpropagation.
Gør man det, ender man med følgende opdateringsregler:
Bemærk her, at vi kender \(z_1^{(m)}\), \(z_2^{(m)}\) og \(o^{(m)}\) på grund af feedforward, mens alle \(u-\), \(v-\) og \(w-\)værdierne er de nuværende værdier af vægtene (inden opdatering).
I alle opdateringsreglerne indgår faktoren
\[ t^{(m)}-o^{(m)} \]
Denne størrelse er et udtryk for den fejl, netværket begår med de nuværende værdier af vægtene (nemlig forskellen på den ønskede targetværdi \(t^{(m)}\) og den prædikterede outputværdi \(o^{(m)}\)). Der er to ting, som er værd at bemærke i den forbindelse:
- Hvis fejlen er stor, bliver vægtene opdateret forholdsvis meget – og omvendt hvis fejlen er lille.
- Når vi har opdateret \(w\)-vægtene, har vi allerede beregnet fejlen \(t^{(m)}-o^{(m)}\). Denne "fejlfaktor" indgår også i opdateringsreglerne for \(v\)- og \(u\)-vægtene, og den allerede beregnede fejl kan altså genbruges, når \(v\)- og \(u\)-vægtene skal opdateres.
- Konsekvensen ved at bruge ReLU er, at vi så at sige kan "tænde" eller "slukke" for om et træningseksempel kommer til at bidrage til opdateringen af enten \(v\)- eller \(u\)-vægtene. Hvis for eksempel \(\delta_v^{(m)}=0\), så kommer det \(m\)’te træningseksempel ikke til at bidrage til opdateringen af \(v\)-vægten og omvendt, hvis \(\delta_v^{(m)} \neq 0\).
Det kan her virke fuldstændig ligegyldigt, om vi skal beregne fejlen et par ekstra gange eller ej, men i virkelighedens anvendelser af kunstige neurale netværk, er det lige præcis denne beregningsmæssige finte, som gør, at det overhovedet kan lade sig gøre at bruge gradientnedstigning. Det sparer nemlig både tid og lagringsplads på computeren, at tidligere beregnede størrelser kan genbruges i de næste opdateringer.
Hvis du gerne vil bevise ovenstående, er der lidt hjælp at hente i nedenstående boks.
Lejlighedspriser med neuralt netværk
Vi vender nu tilbage til eksemplet med lejlighedspriser i Aalborg.
Eksempel 5 (Lejlighedspriser med neuralt netværk) Vi har trænet et kunstigt neuralt netværk med ét skjult lag med henholdsvis to og ti neuroner. Det kan man gøre ved at bruge Neuralt netværk app til regression. Vi har her valgt henholdsvis \(2\) og \(10\) neuroner i det første skjulte lag og \(0\) i det andet skjulte lag. Learning rate er sat til \(0.0001\), antal iterationer til \(1000\) og ReLu er valgt om aktiveringsfunktion i de skjulte lag.
Til sammenligning har vi igen også trænet en kunstig neuron. I alle tre tilfælde har vi beregnet RMSE baseret på træningsdata og på fem folds krydsvalidering.
| Model | RMSE (træningsdata) |
RMSE (krydsvalidering) |
|---|---|---|
| Kunstig neuron | \(0.4972\) | \(0.499\) |
| Neuralt netværk (2) | \(0.4732\) | \(0.4827\) |
| Neuralt netværk (10) | \(0.4203\) | \(0.4449\) |
Ser vi på RMSE fra krydsvalidering, kan vi se, at begge neurale netværk har en mindre RMSE sammenlignet med en kunstig neuron. Det betyder, at et neuralt netværk med skjulte lag i dette eksempel er bedre til at forudsige lejlighedspriser end, hvis vi blot bruger en simpel kunstig neuron (som jo svarer til multipel lineær regression). Det er fordi, at vi med de skjulte lag kan fange nogle ikke-lineære tendenser i data.
I den nedenstående figur har vi igen plottet den faktiske pris (i millioner) ud af \(x\)-aksen og den prædikterede pris op af \(y\)-aksen. I plottet til venstre er de prædikterede priser baseret på en kunstig neuron. I plottet til højre er de baseret på et neuralt netværk med ét skjult lag med ti neuroner.
Sammenligner vi de to plots ovenfor kan man se, at når vi bruger et neuralt netværk med ét skjult lag med ti neuroner, så ligger de prædikterede priser tættere på de faktiske priser. Det svarer til, at punkterne i plottet til højre ligger tættere på linjen med ligning \(y=x\), end de gør i plottet til venstre. Det er altså igen en illustration af, at et neuralt netværk med skjulte lag i eksemplet her er bedre til at forudsige lejlighedspriser end en kunstig neuron.
En anden måde at sammenligne de to modeller på er illustreret i figur 8 og figur 9. I begge figurer er datapunkterne vist sammen med den prædikterede lejlighedspris (her kaldt for prædiktionsfladen), som funktion af lejlighedens areal (\(x_1\)) og alder (\(x_2\)). I figur 8 herunder er den prædikterede pris baseret på en kunstig neuron:
I figur 9 er den prædikterede pris baseret på et neuralt netværk med et skjult lag med ti neuroner:
Det ses tydeligt, at det neurale netværk er bedre til at prædiktere lejlighedspriserne for de nyeste lejligheder med et forholdsvis stort areal sammenlignet med den kunstige neuron. Læg også mærke til, hvordan prædiktionsfladen baseret på det neurale netværk kan "knække" og på den måde modellere ikke lineære sammenhænge i data.
Logaritme-transformerede priser
Uanset hvilken model vi bruger, minimerer vi tabsfunktionen i (1). Lidt forenklet kan den skrives:
\[ E = \frac{1}{2} \sum \left (t-o \right)^2 \] hvor vi altså summerer over hele træningsdatasættet. Her er \(t\) den faktiske lejlighedspris i millioner kroner for en given lejlighed i vores træningsdatasæt, og \(o\) er den tilhørende prædikterede pris, som så kan være baseret på en mere eller mindre kompliceret model.
Vi forestiller os, at vi har to lejligheder, hvor vores model i begge tilfælde skyder \(100000\) kr. forkert. Den ene lejlighed koster \(1.1\) million, mens den anden koster \(10.1\) millioner. Det er skitseret i tabellen herunder:
| Faktisk pris \((t)\) | Prædikteret pris \((o)\) | Absolut afvigelse | Procentvis afvigelse |
|---|---|---|---|
| \(1.1\) | \(1\) | \(0.1\) | \(10 \%\) |
| \(10.1\) | \(10\) | \(0.1\) | \(1 \%\) |
Når vi minimerer tabsfunktionen \(E\), ser vi på forskellen \(t-o\) (det vil sige den absolutte afvigelse). I vores model er der derfor ingen forskel på de to lejligheder, fordi den absolute afvigelse er ens. Man kan sige, at "straffen" for at prædiktere \(100000\) kr. forkert er den samme uanset, om det er en lejlighed til \(1\) million eller til \(10\) millioner. Omvendt kan man se, at den relative afvigelse er på \(10 \%\) for den billige lejlighed, men kun på \(1 \%\) for den dyre lejlighed. Det, kan man nok godt synes, er lidt urimeligt. Det er OK at skyde \(100000\) forkert på en lejlighed til \(10\) millioner, men det er langt værre, hvis lejligheden kun koster \(1\) million.
Lad os se på, hvad der sker, hvis vi logaritme-transformerer \(t\) og \(o\) i tabellen ovenfor:
| Faktisk pris \((t)\) | Prædikteret pris \((o)\) | \(\log(t)\) | \(\log(o)\) | \(\log(t)-\log(o)\) |
|---|---|---|---|---|
| \(1.1\) | \(1\) | \(0.0414\) | \(0\) | \(0.0414\) |
| \(10.1\) | \(10\) | \(1.0043\) | \(1\) | \(0.0043\) |
Her kan vi se, at \(\log(t)-\log(o)\) afspejler, at det ikke er så slemt at skyde \(100000\) forkert, hvis der er tale om en dyr lejlighed i sammenligning med en billig lejlighed. Simpelthen fordi \(\log(t)-\log(o)\) er mindre for den dyre lejlighed sammenlignet med den billige.
Den idé vil vi udnytte. I stedet for at minimere tabsfunktionen hvor de kvadrerede absolutte afvigelser \((t-o)^2\) indgår, vil vi i stedet starte med at tage logaritmen til de faktiske lejlighedspriser \(\log(t)\). Så kommer vi helt automatisk til at modellere en outputværdi, som svarer til logaritme-transformerede prædikterede priser \(\log(o)\). Det vil sige, at vi på den måde kommer til at minimere tabsfunktionen:
\[ E = \frac{1}{2} \sum \left (\log(t)- \log(o) \right)^2 \]
Bruger vi logartime-regnereglen \(\log(a/b) = \log(a)-\log(b)\), kan det omskrives til
\[ E = \frac{1}{2} \sum \left (\log \left (\frac{t}{o} \right )\right)^2 \]
Det vil sige, at vi her grundlæggende minimerer den relative afvigelse mellem den faktiske lejlighedspris og den prædikterede.
Lad og igen se på et eksempel med to lejligheder som koster henholdsvis \(1\) og \(10\) millioner. Men lad os nu sige, at modellen skyder \(10 \%\) under den faktiske pris. Så får vi:
| Faktisk pris i mio. \(t\) |
Prædikteret pris i mio. \(o\) |
\(\frac{t}{o}\) | \(\log \left (\frac{t}{o} \right )\) |
|---|---|---|---|
| \(1\) | \(0.9\) | \(0.9\) | \(0.04576\) |
| \(10\) | \(9\) | \(0.9\) | \(0.04576\) |
Her kan vi se, at bidraget til tabsfunktionen er den samme, fordi den relative afvigelse mellem den faktiske og den prædikterede pris er den samme.