Facit til forløbet "Kandidattest"
NoteFacit til opgave 5
En mulig løsning er, at "flytte" nogle af punkterne meget lidt, hvor de ligger oveni hinanden. For eksempel kan man ændre \(1\) til \(1.05\). Så bliver punkterne synlige, men ligger stadig næsten samme sted. Man kan også bruge Tilfældig(0,0.2) i GeoGebra som genererer et tilfældigt tal mellem \(0\) og \(0.2\).
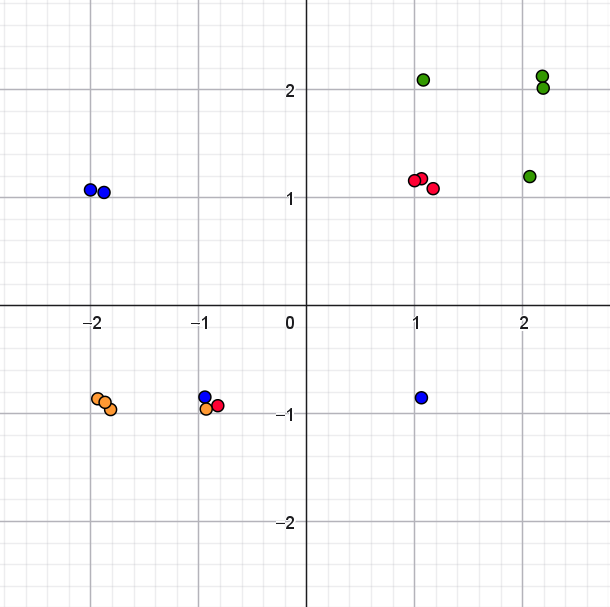
NoteFacit til opgave 7
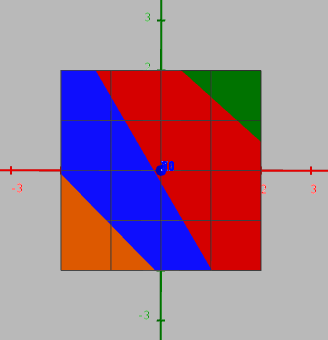
- Enhedslisten og Socialdemokratiet, Socialdemokratiet og Venstre, Venstre og Danmarksdemokraterne.
NoteFacit til opgave 8
| Partier | Ligning |
|---|---|
| S og E | \(-5.33979 \cdot x -5.95406 \cdot y + 14.0861 = 0\) |
| S og V | \(1.00714 \cdot x + 0.58677 \cdot y + 0.1453 = 0\) |
| V og D | \(4.39317 \cdot x + 4.30077 \cdot y + 9.0993 = 0\) |
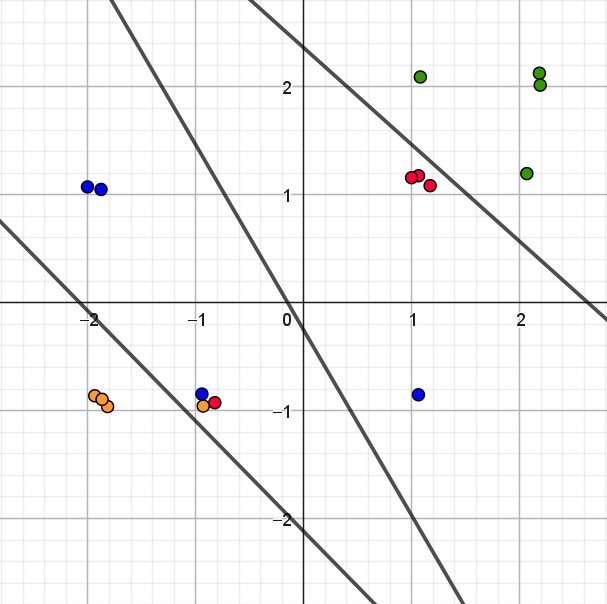
NoteFacit til opgave 10
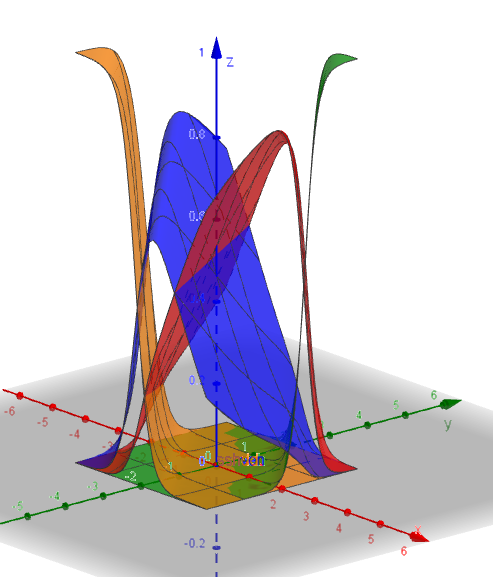
Ja, det giver præcis samme inddeling af \(xy\)-planen. Sandsynlighederne er ens, præcis når scorene er ens.
Det er i midterområdet af hver inddeling, at sandsynligheden er størst. I randen af hver inddeling er sandsynlighed for de to partier, som støder op til hinanden, næsten lige store. Det giver derfor god mening, at sandsynligheden for hvert parti er størst i midten af det område, som hører til det pågældende parti.