Del 4: Tekstgenerering med neurale netværk
Forventet tid ca. 60 min.
Aktivitet 1 - Antal parametre i modellen
Læs afsnittet Neuralt netværk i noten om tekstgenerering med neurale netværk eller se videoerne her:
Vi betragter det kunstige neurale netværk med ét skjult lag, som skal bruges til tekstgenerering:
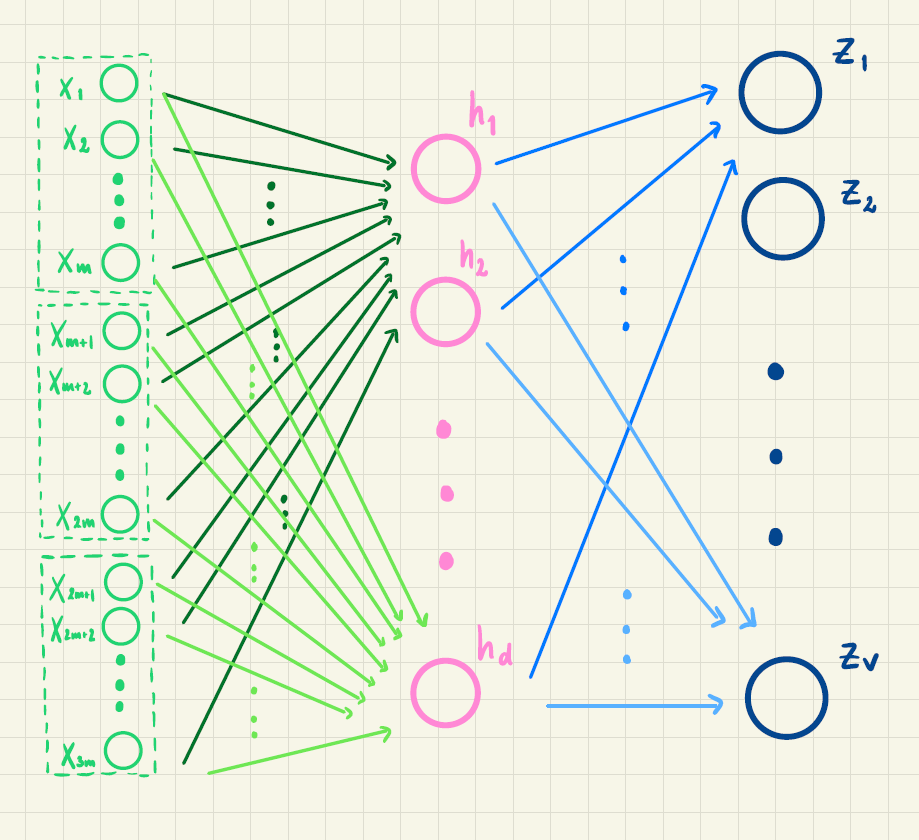
Hvad angiver \(m\), \(d\) og \(V\) i figuren?
Undersøg, hvor mange ord der cirka er i det danske sprog.
Antag, at alle ord repræsenteres ved en 3-dimensionel vektor og at \(d=50\).
Hvor mange vægte indgår der da i det neurale net?
Hvis alle ord repræsenteres ved en 100-dimensionel vektor, hvor mange vægte skal så estimeres?
Undersøg hvor mange vægte (eller parametre, som de også kaldes) de store sprogmodeller har i dag (det præcise antal er en forretningshemmelighed, så du kan ikke finde det præcise svar!).
Aktivitet 2 - Beregning af sandsynligheder med neuralt netværk
Vi forestiller os, at vi har trænet et lille neuralt netværk, der kan beregne sandsynligheden for næste ord baseret på de to foregående ord. For at gøre eksemplet simpelt tillader vi kun to mulige næste ord, nemlig "spinder" og "danser". Inputordene respræsenteres ved to-dimensionale vektorer. Netværket har følgende struktur, hvor outputtet \(z_1\) er sandsynligheden for "spinder", og \(z_2\) er sandsynligheden for "danser":
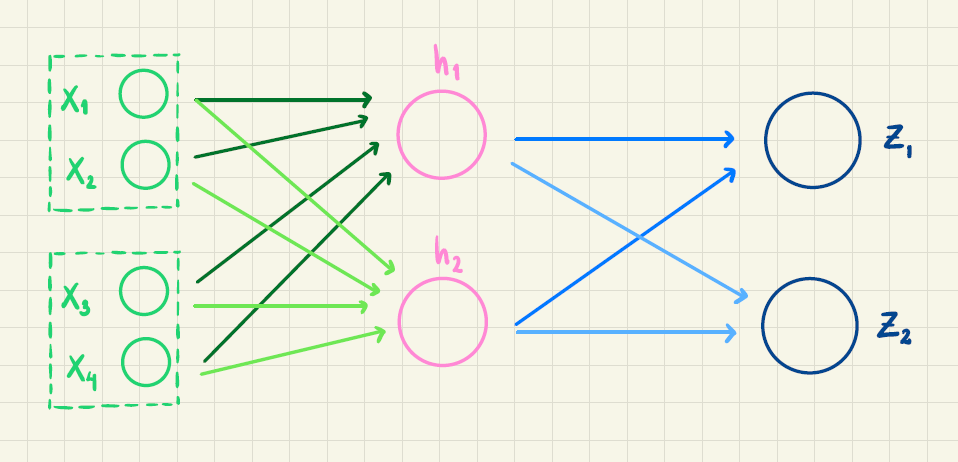
Vægtene, der indgår i første lag er
| \(w_{1,0}\) | \(w_{1,1}\) | \(w_{1,2}\) | \(w_{1,3}\) | \(w_{1,4}\) | \(w_{2,0}\) | \(w_{2,1}\) | \(w_{2,2}\) | \(w_{2,3}\) | \(w_{2,4}\) |
|---|---|---|---|---|---|---|---|---|---|
| \(1\) | \(0\) | \(1\) | \(1\) | \(5\) | \(2\) | \(4\) | \(2\) | \(-1\) | \(3\) |
Vægtene i andet lag er
| \(u_{1,0}\) | \(u_{1,1}\) | \(u_{1,2}\) | \(u_{2,0}\) | \(u_{2,1}\) | \(u_{2,2}\) |
|---|---|---|---|---|---|
| \(0.5\) | \(1\) | \(2\) | \(0.2\) | \(0\) | \(-4\) |
Vægtene er delvist illustreret i figuren her:
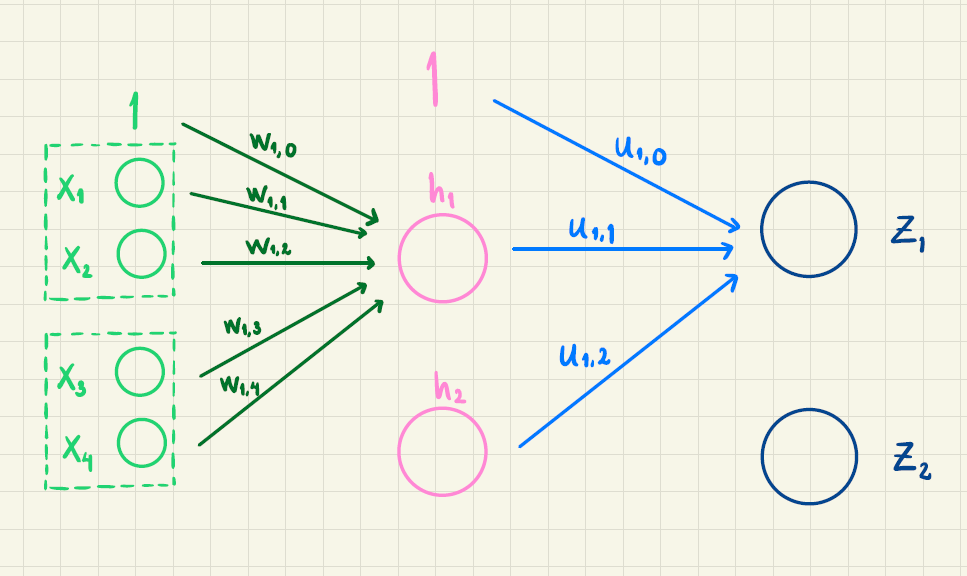
Lad os sige, at vi som input har sætningen "En kat" og skal beregne sandsynligheden for næste ord. Ordene "en" og "kat" har vektorrepræsentationerne \[\vec{v}_{\text{en}} = \begin{pmatrix} 1\\-2\end{pmatrix}, \qquad \vec{v}_{\text{kat}} = \begin{pmatrix} 3\\0 \end{pmatrix}\] Vi vil bruge det neurale netværk til at beregne sandsynligheden for næste ord.
Opstil den 4-dimensionale vektor \(\vec{x}\), der skal bruges som input til netværket, ved at sætte vektorerne \(\vec{v}_{\text{en}}\) og \(\vec{v}_{\text{kat}}\) oven på hinanden.
Beregn \(h_1\) og \(h_2\) ved formlerne \[ \begin{aligned} &h_1= f(w_{1,0} + w_{1,1}x_1 + w_{1,2}x_2 + w_{1,3}x_3 + w_{1,4 } x_4)\\ &h_2= f(w_{2,0} + w_{2,1}x_1 + w_{2,2}x_2 + w_{2,3}x_3 + w_{2,4} x_4) \end{aligned} \] hvor \(f(x)=\frac{1}{1+e^{-x}}\) er den logistiske funktion.
Beregn \(y_1\) og \(y_2\) ved hjælp af formlerne \[ \begin{aligned} &y_1= u_{1,0} + u_{1,1}h_1 + u_{1,2}h_2 \\ &y_2= u_{2,0} + u_{2,1}h_1 + u_{2,2}h_2 \end{aligned} \]
Anvend softmax på \(y_1\) og \(y_2\) for at beregne \(z_1\) og \(z_2\). Det vil sige, beregn \[ \begin{aligned} z_1 &= \frac{e^{y_1}}{e^{y_1} + e^{y_2}}\\ z_2 &= \frac{e^{y_2}}{e^{y_1} + e^{y_2}} \end{aligned} \]
Hvilket af ordene er det mest sandsynlige næste ord?
Aktivitet 3 - Træning af netværk
Læs afsnittet Træning af netværk eller se videoen her:
Aktivitet 4 - Tekstgenerering
Læs afsnittet Tekstgenerering.
Lad os se på prædiktion af det næste ord i sætninger, der ligner disse (men hvor vi ser bort fra punktum og spørgsmålstegn):
En hund løber efter en kat.
Løber en hund efter en kat?
En kat løber ikke efter en hund.
Efter en kat løber en hund.