Opdatering af vægte i et simpelt neuralt netværk med ét skjult lag (men med cross-entropy som tabsfunktion)
Formål
Formålet med dette forløb er gennem detaljerede beregninger at forstå, hvordan vægtene i et neuralt netværk til klassifikation med ét skjult lag opdateres med brug af sigmoid aktiveringsfunktionen og gradientnedstigning med cross-entropy som tabsfunktion.
Dette kan ses som et skridt på vejen til at forstå, hvordan vægtene opdateres i et generelt neuralt netværk.
Et meget lille datasæt
I neurale netværk er der ofte rigtige mange inputvariable (features), rigtigt mange vægte og rigtig mange træningsdata.
For bedre at forstå, hvor vægtene opdateres i et neuralt netværk, vil vi her se på et meget lille eksempel, så det manuelt er muligt at lave opdateringen af vægtene.
Vi vil lave et netværk med 2 inputvariable (\(x_1\) og \(x_2\)), 1 neuron i det skjulte lag (\(y\)) og 1 neuron i outputlaget (\(o\)). Netværket er illustreret i figur 1.
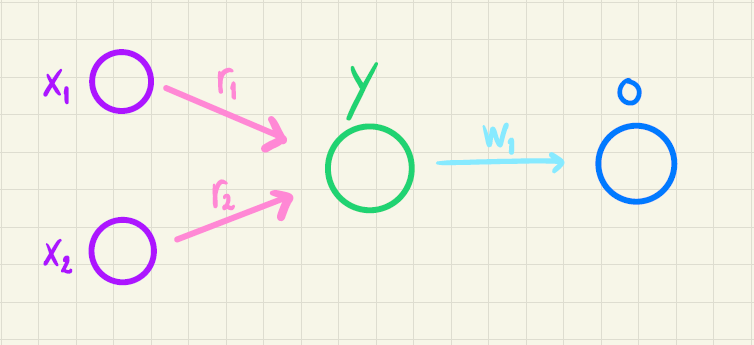
Konkret vil vi se på to features \(x_1\) og \(x_2\) og en targetværdi \(t\) ud fra følgende træningsdatasæt:
| \(x_1\) | \(x_2\) | \(t\) |
|---|---|---|
| 1 | 2 | 0 |
| 2 | 3 | 1 |
| 3 | 7 | 0 |
Vi vælger en learning rate på
\[\eta = 0.1,\]
sigmoid-funktionen som aktiveringsfunktion
\[\sigma(x)=\frac{1}{1+\mathrm{e}^{-x}}\]
og cross-entropy som tabsfunktion \[ E = - \sum_{m=1}^{M} \left( (t^{(m)} \cdot \ln(o^{(m)}) + (1-t^{(m)}) \cdot \ln(1-o^{(m)}) \right) \] Endeligt vælger vi startvægtene fra inputlaget til det skjulte lag som
\[ r_0=0.5 \textrm{ (bias)},\qquad r_1=0.5,\qquad r_2=0.5 \]
og fra det skjulte lag til outputlaget som
\[ w_0=0.5 \textrm{ (bias)}, \qquad w_1=0.5 \]
Plan
Planen er nu følgende:
Lav feedforward fra \(x\) laget til \(y\) laget.
Lav feedforward fra \(y\) laget til \(o\) laget.
Opskriv opdateringsregler for \(w\)-vægtene.
Opdatér \(w\)-vægtene.
Opskriv opdateringsregler for \(r\)-vægtene.
Opdatér \(r\)-vægtene.
Opgaver
Anden opdatering af vægtene
Overvej, om du kan strømline dine beregninger, eventuelt i Excel eller i dit CAS værktøj, så det bliver hurtigere at opdatere vægtene en gang mere på samme måde.
Bemærk, at værdien af tabsfunktionen er blevet lidt mindre. Formålet er jo netop at minimere den gennem gradientnedstigning, så som regel bør værdien bliver mindre, hver gang vægtene opdateres.