Overfitting og krydsvalidering med polynomiel regression
Formål
I dette forløb skal du lære om begreberne overfitting og krydsvalidering ved at lave en række opgaver med brug af polynomiel regression. Du kan læse mere om krydsvalidering i denne note, men kendskab til notens indhold er ikke en forudsætning.
Introduktion
Man vil ofte gerne ud fra kendte observationer i en stikprøve kunne forudsige værdier af fremtidige observationer fra den population, som stikprøven er fra. Dette kaldes prædiktion. I virkeligheden vil man ofte have en stikprøve med 100 eller flere observationer, men for at undgå alt for mange beregninger, nøjes vi her med 8, selvom det i praksis er alt for lidt.
I dette eksempel vil vi se på populationen ”danske gymnasieelever”, hvor vi – indrømmet fjollet – vil undersøge, om der en sammenhæng mellem den uafhængige variabel ”antal biografbesøg det seneste år” og den afhængige variabel ”antal venner på de sociale medier”. Vi lader som om, vi har indsamlet en stikprøve med 8 gymnasieelever med følgende resultat:
| Antal biografbesøg det seneste år | Antal venner på de sociale medier |
|---|---|
| \(1\) | \(14\) |
| \(2\) | \(27\) |
| \(3\) | \(11\) |
| \(4\) | \(19\) |
| \(5\) | \(27\) |
| \(6\) | \(24\) |
| \(7\) | \(12\) |
| \(8\) | \(39\) |
Vi ønsker ud fra disse data at opstille en model, som for nye observationer kan forudsige, hvor mange venner på de sociale medier en gymnasieelev har, hvis man kender antal biografbesøg.
Når man opstiller en model, kan man nogle gange bygge på en forventning eller fysisk model, men andre gange har man som udgangspunkt ikke nogen bestemt idé, hvilket er tilfældet her. Vi vil derfor forsøge at modellere data ved hjælp af et polynomium, hvor vi så skal undersøge, hvilken grad af polynomiet, der ser ud til at kunne klare opgaven bedst. Her ses for eksempel resultatet af regression med et 3. gradspolynomium.
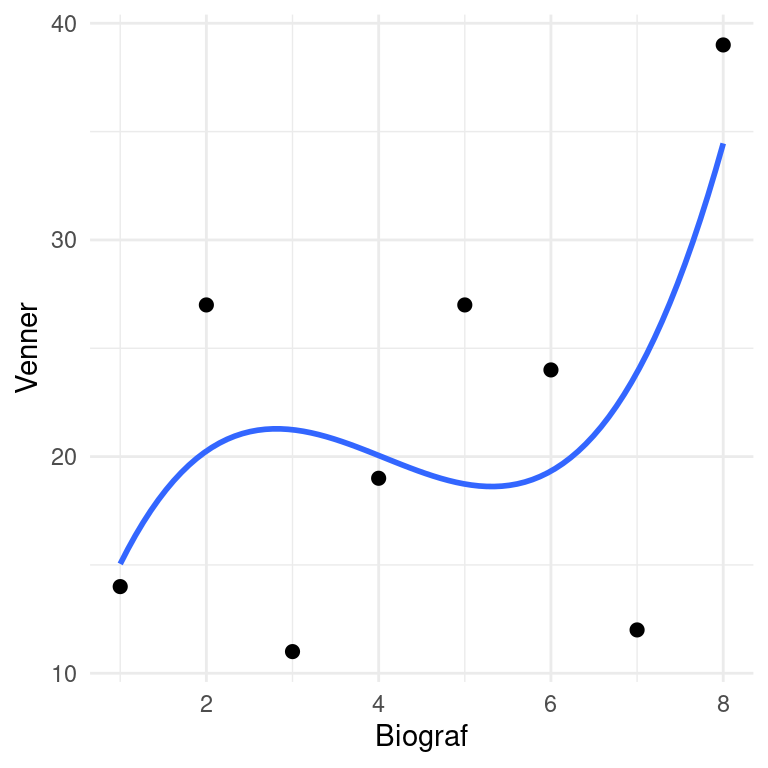
Svaret på opgave 2 bør ikke være overraskende. Desto højere grad af polynomium, desto bedre kan grafen tilpasse sig punkterne. Når graden bliver antallet af punkter minus 1, altså her graden 7, passer grafen perfekt til alle punkterne. Men betyder det så også, at det fundne 7. gradspolynomium passer godt til fremtidige observationer og dermed til at prædiktere, hvor mange venner på de sociale medier andre elever har ud fra antal biografbesøg? Det vil vi undersøge nærmere i resten af forløbet.
Krydsvalidering
Den metode, vi vil anvende, kaldes for krydsvalidering. Vi vil lave regressionen ud fra 6 af de 8 punkter og beregne, hvor godt resultatet heraf passer med de sidste 2 punkter – vi lader så at sige som om, at vi skal prædiktere værdien for de 2 sidste punkter. Det vil vi gøre 4 gange – første gang anvendes punkt 1 og 2 ikke i regressionen, anden gang anvendes punkt 3 og 4 ikke, så anvendes 5 og 6 ikke og til sidst anvendes 7 og 8 ikke.
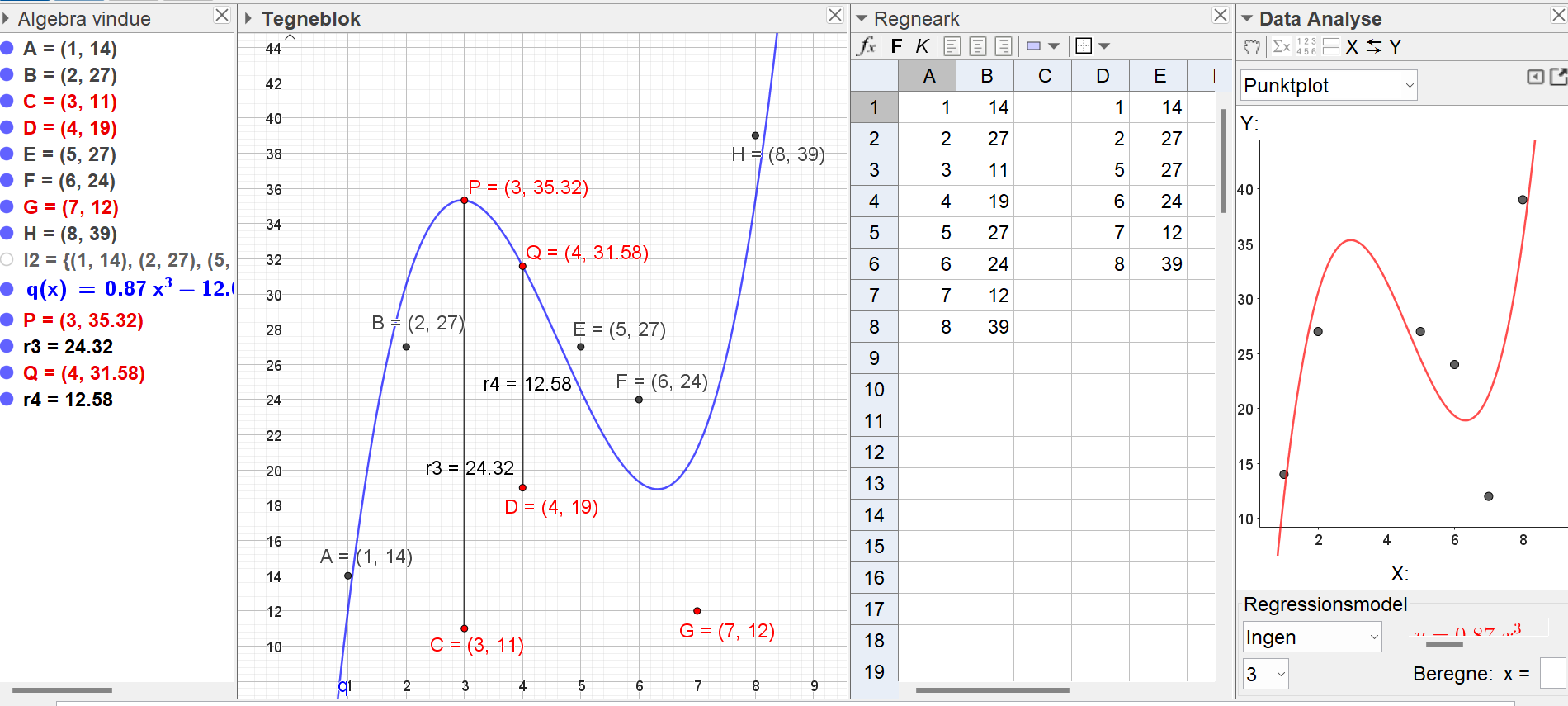
Her er vist et eksempel i GeoGebra. I eksemplet laves 3. gradsregression, hvor punkterne 3 og 4 fjernet. Desuden er den lodrette afstand fra hver af de to fjernede punktet til grafen vist.
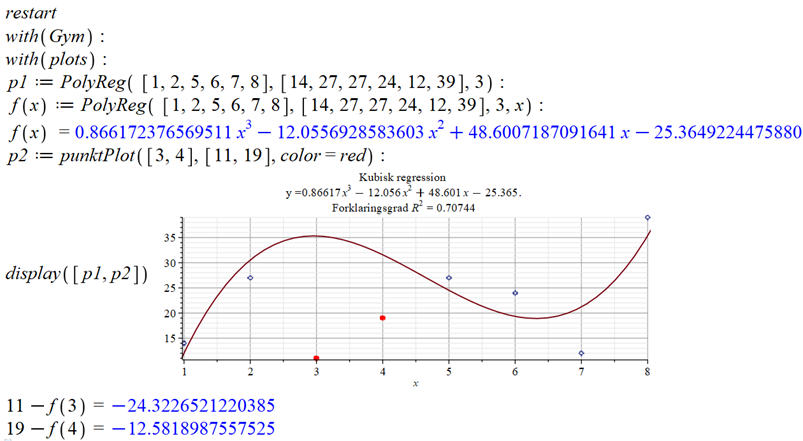
Her ses, hvordan beregningerne kan foretages i Maple.
Som det ses af figuren, ligger det 3. punkt ca. 24,32 under grafen fra regressionen, mens det 4. punkt ligger ca. 12,56 under grafen.
Tabellen nedenfor viser den tilsvarende samlede afstand for hver af graderne 1, 2, 4, og 5.
| Grad | Samlet afstand |
|---|---|
| 1 | 146513 |
| 2 | 142952 |
| 4 | 19821534237 |
| 5 | 66277073433 |
Overfitting
Det fænomen, som dette forløb illustrerer, kaldes for overfitting. Ved at tilpasse modellen for godt til observationerne, får man ikke lavet en passende generel model, men derimod en model til netop disse punkter. Så selvom et 7. gradspolynomium passer perfekt til de 8 punkter, så viste det sig, at den bedste løsning var en noget mindre grad af polynomiet.
Afsluttende
Når man til sidst har bestemt sig for en grad, laver man naturligvis den endelige model vha. alle punkterne, ikke med udeladelse af nogle af dem.
Hvis du og din gruppe er hurtigere færdig end de andre, så læs mere om krydsvalidering i denne note.