Overvågning i Monitorbian
Formål
Nogle lande overvåger deres borgere. Men hvordan gør man mon det? I dette forløb bliver I ansat af efterretningstjenesten i landet Monitorbian for at hjælpe dem med at overvåge deres borgere.
Formålet med forløbet er, at I skal lære at bruge den AI metode, som kaldes for “k nærmeste naboer”. Så kom med til Monitorbian!
Velkommen til Monitorbian
Landet Monitorbian ønsker at blive en vaskeægte overvågningsstat! Men efterretningstjenesten i Monitorbian ved meget lidt om overvågning. Derfor har de ansat jer som intelligence officerer til at løse denne opgave. Tillykke med jeres nye job! Lad os smøge ærmerne op og komme i gang! 😄
I Monitorbian findes der to forskellige slags indbyggere: Nogle nedstammer fra Anders And, mens andre nedstammer fra Fedtmule. På figur 1 kan du se, hvordan de forskellige indbyggere ser ud.

Features
For at overvåge indbyggerne er vi nødt til at identificere nogle egenskaber ved indbyggerne, som kan bruges til at adskille dem fra hinanden. Sådan en egenskab kaldes for en feature. En feature kunne for eksempel være en indbyggers vægt. Det vil være en god feature, hvis de to forskellige slags indbyggere har forholdsvis forskellig vægt. En anden feature kunne være øjenfarve, men hvis det ikke på en eller anden måde kan være med til at skelne de to slags indbyggere fra hinanden, så vil øjenfarve være et dårlig valg af feature i denne sammenhæng.
Træningsdata
Som I lige har set i opgave 1, er der rigtig mange egenskaber ved indbyggerne, der kan bruges som features. Men som intelligence officerer er vi nødt til at træffe et valg og beslutte os for, hvad vi vil gå videre med. I har derfor netop været til møde i sikkerhedsudvalget, hvor det er blevet besluttet, at højde (målt i \(cm\)) og fodareal (målt i \(cm^2\)) er de to features, som I skal arbejde videre med. Disse to features er forholdsvis nemme at scanne, og fremadrettet bliver det derfor sådan, at hver gang en indbygger i Monitorbian går ind i en offentlig bygning, så bliver vedkommende scannet og højde og fodareal bliver målt.
I skal nu have lavet en algoritme1, som kan forudsige, hvilken slags indbygger der er tale om – alene baseret på viden om en given indbyggers højde og fodareal. Man siger, at vi gerne vil klassificere indbyggerne – her i to klasser: Anders And og Fedtmule.
1 Tænk på en algoritme som en slags opskrift, som kan bruges til at forudsige hvilken slags indbygger, der er tale om.
2 Man siger også, at vi gerne vil prædiktere hvilken slags indbygger, der er tale om.
For at gøre det har vi brug for træningsdata. Træningsdata består af en masse data fra forskellige indbyggere, hvor de to features er blevet målt samtidig med, at det for hver indbygger er angivet om vedkommende nedstammer fra Anders And eller fra Fedtmule. Denne sidste oplysning er jo lige præcis den oplysning, som vi gerne fremadrettet vil kunne forudsige2. I træningsdata angiver vi altså den værdi, som vi gerne vil prædiktere. Derfor kalder man også denne værdi for en targetværdi.
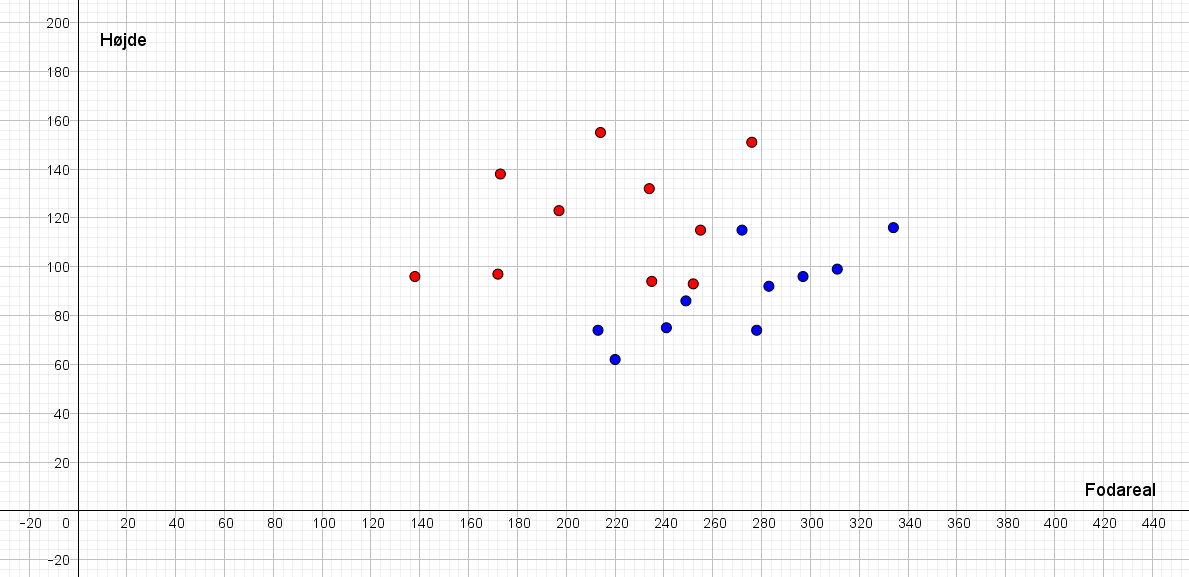
Nedenstående viser en tabel med træningsdata3, men targetværdien mangler. Angiv targetværdien ("Anders And" eller "Fedtmule").
| Indbygger | Fodareal (\(cm^2\)) | Højde (\(cm\)) | Targetværdi |
|---|---|---|---|
 |
197 | 123 | |
 |
214 | 155 | |
 |
255 | 115 | |
 |
297 | 96 | |
 |
213 | 74 | |
 |
173 | 138 | |
 |
272 | 115 | |
 |
235 | 94 | |
 |
311 | 99 | |
 |
334 | 116 | |
 |
276 | 151 | |
 |
283 | 92 | |
 |
234 | 132 | |
 |
172 | 97 | |
 |
278 | 74 | |
 |
241 | 75 | |
 |
220 | 62 | |
 |
249 | 86 | |
 |
138 | 96 | |
 |
252 | 93 |
3 Billederne er i øvrigt genereret med en AI billedgenerator i programmet craiyon.
Nærmeste naboer (kNN)
Der findes en lang række af metoder til at lave klassifikation, som er det, vi har brug for her. Nogle af dem bruger meget avanceret matematik og enorme computerkræfter og kan anvendes til diagnosticering af sygdomme, klassificere dokumenter i forskellig typer, genkende objekter i billeder og videoer. Helt så avancerede metoder får vi dog ikke brug for her.
Vi vil i stedet fokusere på én af de simpleste, men alligevel effektive metoder til at klassificere observationer. Metoden kaldes på engelsk k-nearest neighbors eller på dansk k-nærmeste naboer, og forkortes ofte som kNN. kNN er baseret på den simple antagelse, at observationer, som er tæt på hinanden, også ligner hinanden. I vores eksempel vil det være, at indbyggere, som har cirka samme højde og fodareal, vil vi antage, hører til i den samme klasse.
For at bestemme hvilke naboer, der ligger tæt på hinanden, er vi nødt til at kunne beregne afstanden mellem to punkter. Du husker nok, at afstanden \(d\) mellem punktet \(P(x_1,y_1)\) og punktet \(Q(x_2,y_2)\) er
\[ d = \sqrt{(x_2-x_1)^2+(y_2-y_1)^2} \tag{1}\]
På figur 2 nedenfor ser I de træningsdata, som I selv angav en targetværdi for i den foregående opgave. Måske var det for nogle af indbyggerne svært at afgøre oprindelsen alene ved at se på billedet – og måske var det nemt nok, men her ses i hvert tilfælde den korrekte klassificering4.
4 Man kan forestille sig, at en sådan klassificering er baseret på yderligere test og undersøgelser, som man normalvis ikke vil have til rådighed.

Når \(k\)-nærmeste naboer bruges til at klassificere en ny indbygger benyttes en flertalsafstemning (også kaldet majoritetsbeslutning). Det vil sige, at en ny indbygger bliver prædikteret til at tilhøre den klasse, som de fleste af indbyggerens \(k\)-nærmeste naboer tilhører. Hvis for eksempel \(k=5\), og vi har en ny indbygger, som vi gerne vil afgøre klassen for, så ser vi simpelthen på de 5 nærmeste naboer til denne indbygger og tæller op, hvilke klasser de tilhører. Hvis to af dem nedstammer fra Anders And og tre fra Fedtmule, så vil en flertalsafstemning sige, at den nye indbygger nok er i Fedtmule-klassen. Man kan komme ud for, at præcis halvdelen af de \(k\) nærmeste naboer nedstammer fra Anders And, mens præcis den anden halvdel nedstammer fra Fedtmule. I det tilfælde vil vi sige, at klassifikationen er uafklaret.
Denne idé vil vi nu bruge.
Valg af \(k\) og testdata
Som du har set ovenfor, vil forskellige valg af \(k\) give forskellige resultater. Så hvordan vælger vi mon den bedst mulige værdi af \(k\)? For at afgøre det vil vi opdele vores data i to dele: træningsdata og testdata. Det kunne for eksempel være sådan, at af alle de data vi har, så bruger vi 80% som træningsdata. Det er træningsdata, som vi bruger til at lave prædiktionen med. De resterende 20% af data vil vi lade være testdata, hvor vi bruger testdata til at måle, hvor nøjagtig vores algoritme er.
Idéen er nu denne:
- Vi vælger en værdi af \(k\) – det kunne for eksempel være \(k=5\).
- Vi ser så på hver eneste indbygger i testdata og lader som om, at vi ikke kender denne indbyggers oprindelse. Det vil sige, at vi lader som om, at vi ikke kender targetværdien. Vi vil nu bruge træningsdata til at lave en prædiktion for denne indbygger baseret på den valgte værdi af \(k\). Men da vi jo i virkeligheden godt kender denne indbyggers oprindelse, så får vi nu mulighed for at afgøre, om prædiktionen er rigtig eller forkert.
Lad os forestille os, at vi har 500 data i alt, og at vi lader 20% af disse være testdata. Det vil sige, at testdata består af 100 datapunkter. For hvert af disse datapunkter laver vi en prædiktion. Så enten prædikterer vi, at datapunktet er blåt eller rødt baseret på en flertalsafstemning af de \(k\) nærmeste naboer i træningsdatasættet. Holder vi denne prædiktion op mod den faktiske værdi, kan vi opstille en såkaldt confusion tabel. Et eksempel på en sådan ses her:
| Prædikteret blå | Prædikteret rød | |
|---|---|---|
| Faktisk blå | 56 | 9 |
| Faktisk rød | 7 | 68 |
Der er 140 datapunkter i alt, og vi kan her se, at 56 datapunkter blev prædikteret til at være blå og faktisk også er blå. Tilsvarende er 68 af datapunkterne prædikteret til at være røde, mens de faktiske også er røde. I alt 7+9=16 datapunkter har fået prædikteret en forkert farve sammenlignet med deres faktiske farve. Altså kan vi her se, at med den valgte værdi af \(k\) har vores kNN algoritme lavet en fejl i \[ \frac{16}{140} \approx 11.4 \% \] af tilfældene, mens den har prædikteret korrekt i \[ \frac{56+68}{140} = \frac{124}{140} \approx 88.6 \% \] af tilfældene. Vi kan nu lave tilsvarende beregninger for forskellige værdier af \(k\) og helt enkelt vælge den værdi af \(k\), som giver den mindste fejlprocent, når vi tester på vores testdata.
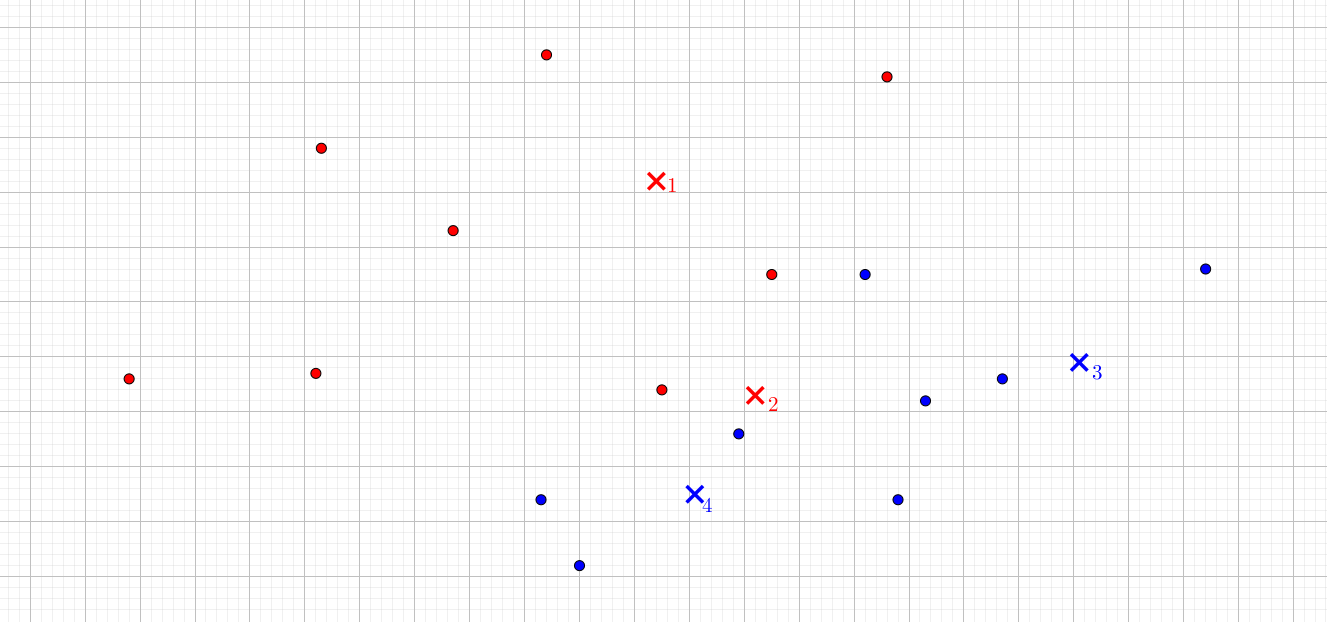
Vi ser nu igen på vores simple datasæt, og deler det op i et træningsdatasæt og et testdatasæt. På figur 4 er testdata markeret med et kryds. Vi vil for forskellige værdier af \(k\) prædiktere farven på testdata (samtidig med at vi jo godt kender den faktiske værdi).
kNN i programmet Orange
Her til sidst skal vi lege lidt med et gratis program, som hedder Orange. Du kan få hjælp til at installere programmet her.
Start med at se denne video:
Det er også muligt at bruge kNN uden selv at udvælge features. I stedet kan man bruge billederne fra tabellen i opgave 2 direkte. Se her hvordan man gør det:
Videre overvejelser
Der er flere ting, man kunne overveje at arbejde videre med. For eksempel kunne man sagtens forestille sig, at det kunne give mening med mere end to features. Afstandsformlen i (1) kan faktisk sagtens udvides til flere dimensioner end to. Man finder eksempelvis afstanden mellem to punkter \((x_1,y_1,z_1)\) og \((x_2,y_2,z_2)\) i et tredimentionelt koordinatsystem på denne måde: \[ d = \sqrt{(x_2-x_1)^2+(y_2-y_1)^2+(z_2-z_1)^2} \] Og det er nok ikke svært at forestille sig, at man kan udvide denne formel yderligere. Det betyder, at man stadig kan bruge \(k\) nærmeste naboer som metode i det tilfælde, hvor man har mere end to features.
En anden ting at overveje er den skala, vi måler features på. Vi har for eksempel valgt at måle i \(cm^2\) og i \(cm\). Men hvad hvis vi havde målt i \(m^2\) og i \(m\)? Det er faktisk ikke helt ligegyldigt hvilken skala, man bruger, og derfor vælger man som regel også at skalere alle ens data, så de kommer på en sammenlignelig skala. Det kan du læse meget mere om i vores materiale om feature-skalering.