Kan vi genkende håndskrevne tal?
Formål
Nogle gange har man brug for, at håndskrevet tekst kan digitaliseres. Det kan for eksempel være i en eksamenssituation, hvor din lærer og censor skriver din karakter på en liste, som efterfølgende skal tastes ind på en computer. Det ville være smart, hvis man kunne scanne listen eller tage et billede af den, hvorefter alle tal korrekt vil blive genkendt (så du ikke får en forkert karakter!). Dette forløb handler om, hvordan det kan gøres.
RGB-farvemodellen
Vi skal først se lidt på, hvordan billeder bliver repræsenteret i en computer. Prøv at finde et billede på din computer og zoom ind så meget som muligt. Du vil opdage, at billedet i virkeligheden består af en masse små kvadrater, som hver især har én farve. Sådan et kvadrat kaldes for en pixel.
Hver pixel består af tre subpixels. Den første subpixel kan lyse Rød, den anden Grøn og den tredje Blå:
Fordi alle farver bliver repræsenteret ved disse tre farver, taler man om en RGB-farvemodel.
Vi kan skrue på lysstyrken i hver af de tre subpixels. Hvis der er skruet fuldt op for farven, er værdien 255, mens helt slukket svarer til værdien1 0.
1 Tallene fra 0 til 255 kan i det binære talsystem repræsenteres ved 8 bits svarende til 1 byte, fordi \(2^8=256\).
Vores øje opfatter ikke farven på de tre subpixels individuelt, men vi ser i stedet en blandingsfarve. Hvis der for eksempel er skruet fuldt op på alle tre farver, så vil vores øje opfatte det som hvid. Det vil sige, at den pixel, som er vist i figur 1 vil lyse hvid for os!
Skruer vi helt op for rød og blå, men slukker for grøn fås en pink farve (som kaldes for magenta):

Farven skrives:
rgb(255,0,255)
Hvis der er skruet lige meget op for den røde, grønne og blå subpixel, fås forskellige nuancer af grå. Det er der vist eksempler på her:

Det betyder, at hvis man udelukkende er interesseret i gråskalaværdier, så kan vi nøjes med én værdi, som er den fælles værdi for rød, grøn og blå:
MNIST datasættet
Der findes et stort datasæt – det såkaldte MNIST datasæt2, hvor man har samlet 60000 håndskrevne cifre. Datasættet består af 60000 rækker, som hver repræsenterer et håndskrevet ciffer mellem \(0\) og \(9\). Der er i alt 785 kolonner. Den første kolonne kaldet "label" angiver hvilket ciffer, der er tale om. Det er den værdi, som vi i sidste ende gerne vil kunne forudsige. En sådan værdi kaldes også for en targetværdi. De resterende 784 kolonner angiver gråskalaværdierne fra et \(28 \times 28\) pixel billede af et håndskrevet ciffer.
2 MNIST står for "Modified National Institute of Standards".
På figur 5 ses et håndskrevet "0" fra MNIST datasættet.
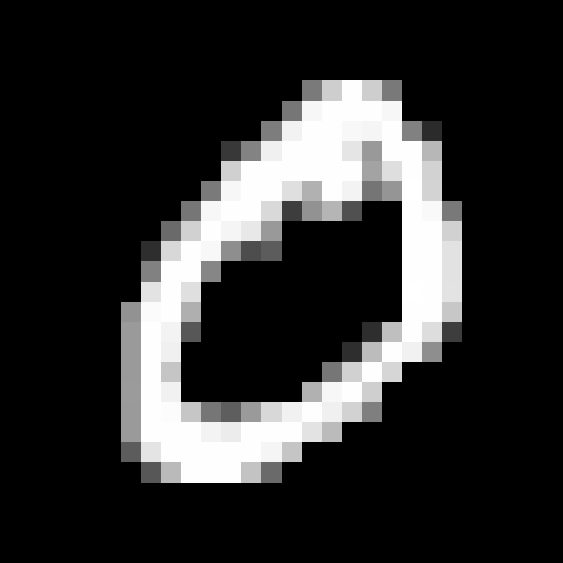
Bemærk, at der er skrevet med hvid på sort baggrund. Når vi i det følgende viser billederne af de håndskrevne tal, har vi valgt at vende farveskalaen om, så vi i stedet for gråskalaværdien \(x\) tegner en pixel med gråskalaværdi
\[ 255-x \]
Det betyder, at vi i stedet for sort viser hvid og omvendt. Dette er illustreret på figur 6.
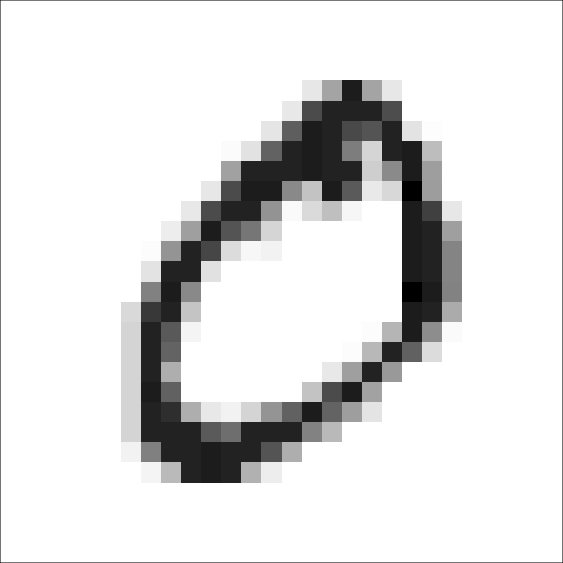
Vi skal nu prøve, om vi ud fra de 784 gråskalaværdier kan "udvinde" nogle få, men sigende værdier, som kan bruges til at forudsige, hvilket ciffer der er på billedet. I første omgang vil vi prøve, om vi kan kende forskel på 0- og 1-taller.
Det første, vi vil gøre, er at lave billederne i en lavere opløsning svarende til, at billederne bliver mere pixeleret. Vi vil for eksempel lave et \(7 \times 7\) pixel billede ved at inddele det oprindelige \(28 \times 28\) pixel billede i \(2 \times 2\) pixels, hvor vi så tager gennemsnittet af de fire pixelværdier. Et eksempel på det ses i figur 7:
Til trods for at billedet er meget mere pixeleret, kan man faktisk stadigvæk tydeligt se konturerne af 0’et. Til sammenligning er et billede af et 1-tal vist i figur 8:
Kan vi kende forskel på 0 og 1?
Idéen er, som nævnt tidligere, at vi ud fra \(7 \times 7\) billederne vil udvinde nogle nye og få værdier, som kan bruges til at kende forskel på \(0\)- og \(1\)-tallerne. Vi vil altså gerne koge de ialt 49 pixelværdier ned til en til tre værdier, som er nok til at adskille 0 fra 1. Sådanne værdier kaldes for features.
Det kunne godt se ud som om, at der bruges flere farvede pixels på at skrive et 0, end der bliver brugt på at skrive et 1-tal. Vi vil derfor helt enkelt udregne den gennemsnitlige pixelværdi af hele billedet:
- Udregn den gennemsnitlige pixelværdi for nedenstående to billeder:
![]()
Et andet bud på en simpel feature er at tælle hvor mange pixels, der er helt hvide (det vil her sige med en pixelværdi på 0, fordi vi har vendt farveskalaen om). Vi vil nemlig forvente, at et 1-tal fylder mindre end et 0, så antallet af helt hvide pixels må forventes at være større på billederne af 1-taller.
Tæl antallet af helt hvide pixels på ovenstående to billeder.
Vi har nu beregnet to forskellige features for de to billeder. Er værdierne som forventet?
Det er klart, at den gennemsnitlige pixelværdi og antallet af helt hvide pixels hænger sammen. Forklar med ord hvilken sammenhæng, man vil forvente.
Det bliver selvfølgelig lidt møjsommeligt at udregne disse to features for mange billeder. Derfor skal vi nu bruge en app, som gør arbejdet for dig.
Når du åbner datasættet i Excel, skulle det gerne se sådan her ud:
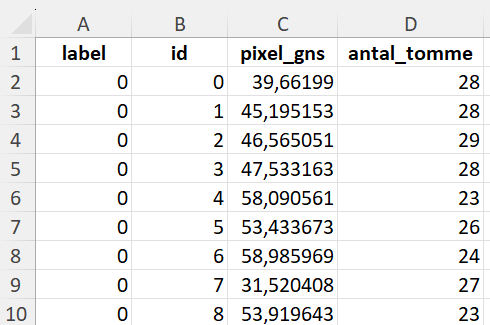
Den første kolonne ("label") angiver, om der er tale om et billede af et 0 eller et 1-tal. Den anden kolonne ("id") er billedets id (det kan du bruge til at få vist billedet i app’en), de to sidste kolonner ("pixel_gns") og ("antal_tomme") svarer til de features, som vi beregnede i opgave 1.
3 Man får her en forholdsvis høj klassifikationsnøjagtighed. Det er i virkeligheden lidt snyd. Vi finder nemlig ud af, hvor god modellen er til at klassificere de billeder, som modellen er trænet på. I virkeligheden bør man undersøge, hvor god modellen er til at klassificere nye, ukendte billeder. Et sådant datasæt med nye og ukendte billeder kalder man for et testdatasæt. Det kan du læse mere om i noten Overfitting, modeludvælgelse og krydsvalidering.
I opgave 6 ovenfor kom du formentlig frem til, at hvis vi alene skal adskille 0’er fra 1-taller, så er det faktisk nok at tælle antallet af hvide pixels i billedet! Gør vi det, kan vi med vores træningsdata få en klassifikationsnøjagtighed på \(98.5\%\).
Hvad med 0 og 3?
Det går jo strygende! Tæl antallet af hvide pixels i billedet, og du kan kende forskel på 0 og 1. Men hvad nu, hvis vi vil kende forskel på 0 og 3. Går det mon lige så nemt? Et eksempel på et håndskrevet 0 og 3-tal er vist i figur 9.
Lad os prøve igen med de to features: gennemsnitlig pixelværdi og antal hvide pixels.
Det er ret tydeligt, at den gennemsnitlige pixelværdi og antallet af hvide pixels i billedet på ingen måde kan bruges til at kende forskel på 0 og 3. Det skyldes, at man åbenbart bruger cirka lige meget "blyantsfarve" på at skrive 0, som man gør på at skrive 3. Det viser med al tydelighed, at de features, som er gode at vælge, er fuldstændige afhængige af det klassifikationsproblem, som man står med. To features kan være formidable til ét klassifikationsproblem (at kende forskel på 0 og 1), mens de er elendige til et andet klassifikationsproblem (at kende forskel på 0 og 3). Det betyder, at vi må på jagt efter nye features!
Vandrette lokale maksima
På figur 10 ses et billede af et håndskrevet 0 og 3-tal i en opløsning på \(7 \times 7\) pixels, og vi skal prøve at finde nogle karakteristika ved de to billeder, som kan bruges til at adskille dem.
På figur 11 har vi lagt et vandret vindue ind over en enkelt række af pixels på de to billeder.
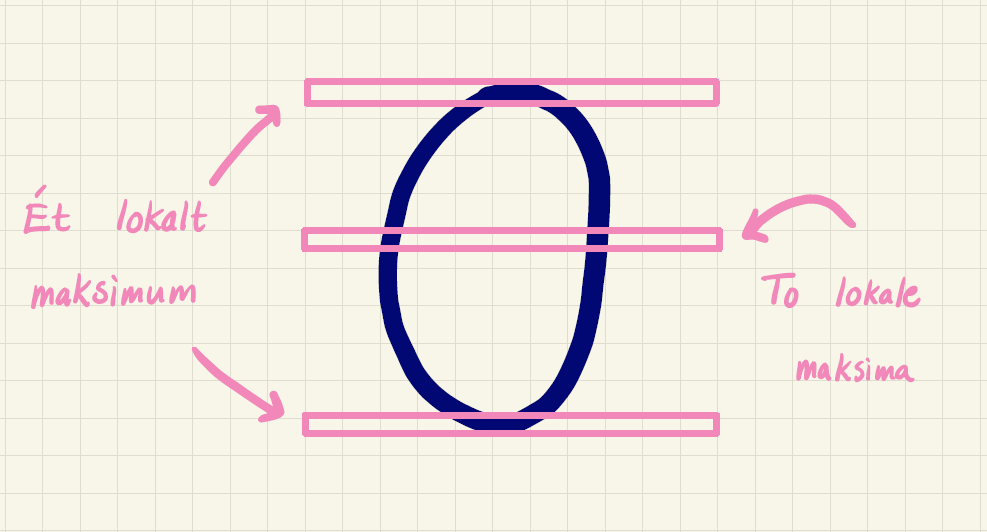
Vi vil her tælle, hvor mange gange pixelværdierne "topper". En sådan "top" kalder vi for et lokalt maksimum. På billedet af 0, kan vi se, at der er to lokale maksima, mens der på billedet af 3-tallet kun er ét lokalt maksimum.
Men antallet af "toppe" ændrer sig alt efter, hvor vi placerer det vandrette vindue. På et billede af et 0 er dette illustreret på figur 12. Hvis vi ser på de vandrette pixelværdier, vil vi i "toppen" og "bunden" af 0’et forvente ét lokalt maksimum, mens vi for mange af de vandrette vinduer i midten af 0’et vil tænke, at der ofte vil være to lokale maksima.
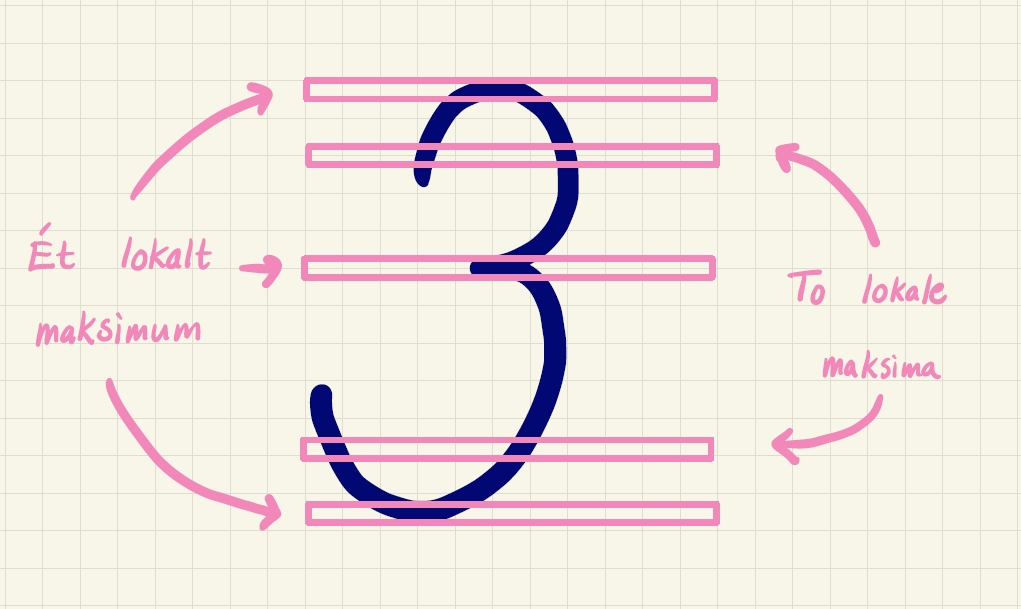
Ser vi derimod på vandrette pixelværdier på et billede af et 3-tal, vil der både være ét og to lokale maksima, som illustreret på figur 13.
Lodrette lokale maksima
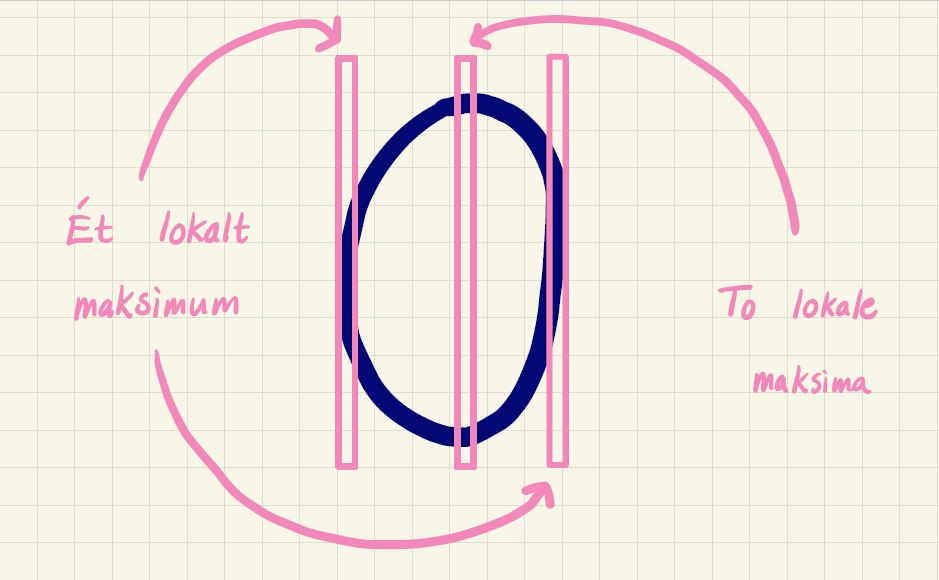
Lægger vi derimod et lodret vindue ind, vil der på et 0 typisk være ét eller to lokale maksima (se figur 14).
På et 3-tal kan der derimod være mellem ét og tre lokale maksima (se figur 15).
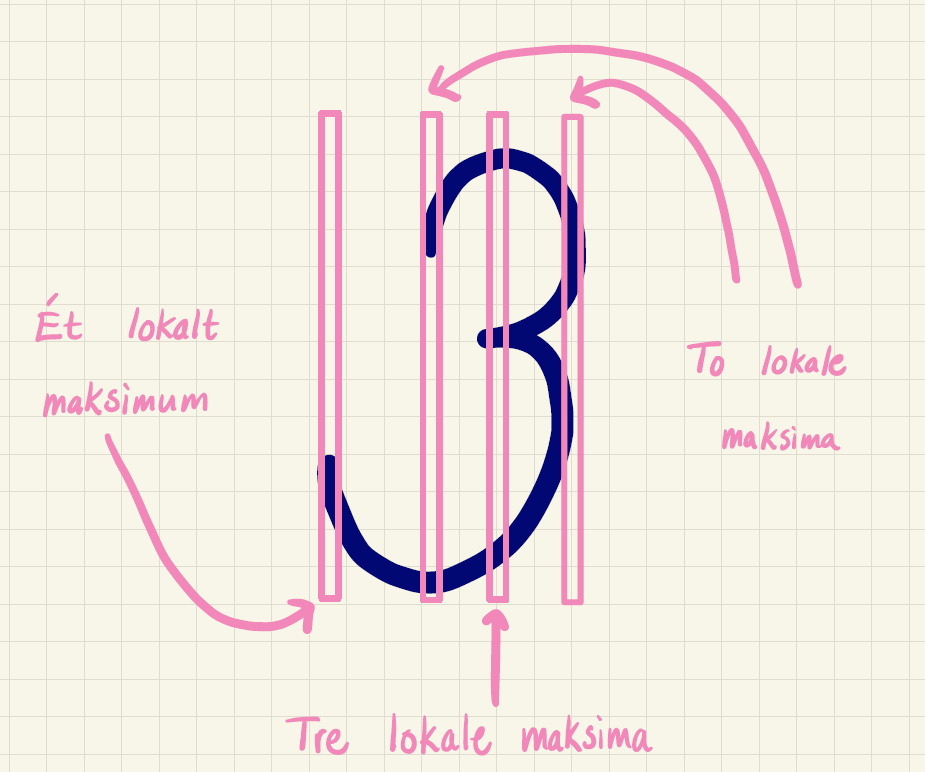
Et konkret eksempel er vist i figur 16. På billedet af 0’et til venstre er der som forventet to lokale maksima, mens der på billedet af 3-tallet til højre som forventet er tre lokale maksima.
![]()
Vandrette maksima
Med udgangspunkt i ovenstående billede af et 0 og et 3-tal skal du:
- Bestem antallet af lokale maksima i alle vandrette rækker.
Vi ser nu bort fra de rækker, hvor der ikke var nogle maksima:
Udregn det gennemsnitlige antal vandrette lokale maksima.
Bestem det største antal lokale maksima i alle vandrette rækker.
Lodrette maksima
Med udgangspunkt i ovenstående billede af et 0 og et 3-tal skal du:
- Bestem antallet af lokale maksima i alle lodrette søjler.
Vi ser nu bort fra de søjler, hvor der ikke var nogle maksima:
Udregn det gennemsnitlige antal lodrette lokale maksima.
Bestem det største antal lokale maksima i alle lodrette søjler.
I opgave 11 så vi, at de håndskrevne tal ikke altid helt opfører sig, som vi kunne forvente i forhold til antallet af lodrette og vandrette lokale maksima. Tallene er simpelthen nogle gange skrevet lidt skørt, så der enten er flere eller færre lokale maksima end forventet. Men det kunne jo godt være, at der vil være information at hente, hvis vi ser på de gennemsnitlige værdier af de lodrette og vandrette lokale maksima. Det prøver vi i næste opgave.
Når vi ser på nogle af de cifre, som vi ikke fik klassificeret korrekt, kan det måske godt undre, hvad der går galt. På figur 17 kan vi se et 0 (med id 8), som vi ikke får klassificeret korrekt. I forhold til det punktplot, du lige har lavet, ligger dette ciffer for langt til højre. Det vil sige, at det gennemsnitlige antal lodrette maksima er for stort (vi forventer måske en værdi på omkring \(1.8\)). Det kan vi også se på figur 17. Der er flere søjler med \(3\) og \(4\) lodrette maksima, hvilket samlet set resulterer i et gennemsnit på \(3.33\). Men hvorfor egentlig? Det er da et nydeligt, rundt 0! Forklaringen skal findes i tykkelsen af stregen og den måde, tallet er tegnet på. Personen, der har tegnet 0’et, har tegnet tykt, men ikke været i stand til at lægge et jævnt tryk hele vejen rundt. Det betyder, at der lodret er opstået flere lokale maksima, end vi vil forvente.

Man kunne derfor få den tanke, at dette fænomen, som jo ikke kan bruges til at kendetegne cifret, måske kan undgås, hvis vi ser på en lavere pixel-opløsning. I figur figur 18 ses det samme ciffer, men med en pixel-opløsning på henholdsvis \(7\) og \(14\).
Her kan vi se, at det forventede antal lodrette og vandrette maksima i en pixel-opløsning på \(7\), som forventet ligger mellem \(1\) og \(2\), mens der i den højere pixel-opløsning på \(14\) sniger sig nogle søjler ind med \(3\) lodrette maksima.
Vi vil derfor nu undersøge, om vi kan få en højere klassifikationsnøjagtighed ved at bruge en pixel-opløsning på \(7\).
Klassificering ved beregning (kan udelades)
Nogle gange er det svært med øjemål at se, om et punkt lige præcis ligger over eller under en linje. Andre gange kan det være umuligt præcist at tælle, hvor mange cifre der er klassificeret forkert, fordi nogle af punkterne ligger oveni hinanden. Men vi kan heldigvis beregne om et punkt ligger over eller under linjen. Det gøres ved at betragte den lodrette forskel fra et punkt og ned til linjen4.
4 Med mindre skillelinjen er lodret!
Dette er illustreret i figur 19:
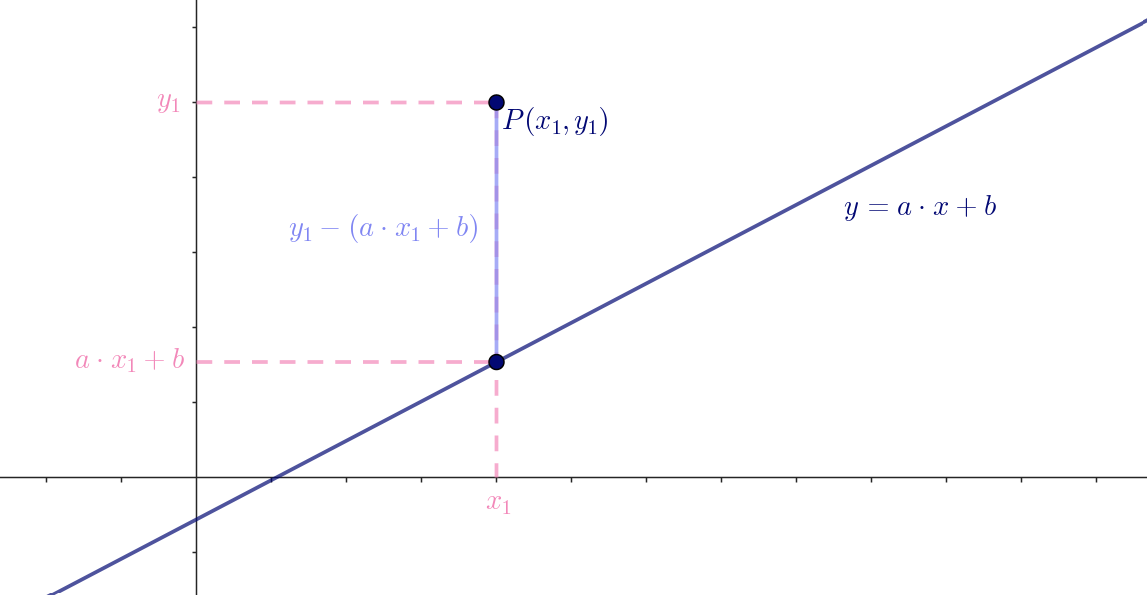
Den lodrette forskel fra punktet \(P(x_1,y_1)\) ned til linjen med ligning \(y= a \cdot x + b\) må være (se figur 19):
\[ y_1 - (a \cdot x_1 + b) \] Hvis denne forskel er positiv, ligger punktet over linjen og omvendt, hvis forskellen er negativ.