Del 4: Træning af kunstig neuron
Forventet tid ca. 1 x 90 min.
Aktivitet 3 handler om et eksempel på "slow learning" og kan derfor springes over.
Aktivitet 1 - Datasæt
De træningsdata i tabel 1, som vi har brugt i de foregående aktiviteter, er i virkeligheden alt, alt for simple.
| Nr. på træningseksempel \(m\) | Kundens alder \(x^{(m)}\) | Targetværdi \(t^{(m)}\) |
|---|---|---|
| \(1\) | \(25\) | \(0\) |
| \(2\) | \(40\) | \(0\) |
| \(3\) | \(60\) | \(1\) |
For det første er tre træningseksempler alt for få. For det andet kan man jo bare kigge på træningsdata og lave en regel ud fra dem. Det kunne for eksempel være: Hvis kunden er 55 år eller under, så tror vi ikke, at hun vil aktivere tilbuddet, og omvendt hvis kunden er over 55 år. Det behøver man jo ikke fancy AI metoder til at indse! For det tredje er det urealistisk, at alder alene kan afgøre, om en kunde aktiverer et tilbud eller ej. Man vil typisk inddrage andre inputvariable som for eksempel køn, forbrug og så videre.
Vi vil derfor her se på et langt mere realistik eksempel, hvor træningsdatasættet er større og med flere inputvariable.
I datasættet er der tre inputvariable: "alder" (målt i år), "forbrug" (målt i kroner) og "køn" (kon, hvor 0 svarer til kvinder og 1 svarer til mænd). Targetvariablen kaldes for "aktiveret" (hvor "ja" svarer til, at kunden har aktiveret tilbuddet, og "nej" svarer til, at kunden ikke har aktiveret tilbuddet). Vi har altså følgende inputvariable:
- \(x_1\): kundens alder målt i år
- \(x_2\): kundens forbrug i Good Food den seneste måned målt i kr.
- \(x_3\): kundens køn (0 svarer til kvinder og 1 svarer til mænd)
I den næste opgave skal vi prøve at lave to plots for at visualisere datasættet.
Vi laver først et plot for kvinderne.
Start med at kopiere den første halvdel af datasættet over i et regneark i GeoGebra svarende til data for alle kvinderne, det vil sige, hvor "kon=0" (heldigvis er datasættet sorteret efter "kon", så det er lige til at gå til).
I celle
E2skriver du(A2,B2). Det giver dig koordinatsættet for alder og forbrug for det første træningseksempel.Tag ved den lille kasse i nederste hjørne af celle
E2og trække ned, så du får udfyldt kolonneEfor hele datasættet.Gå over i "Tegneblokken" og ændr på akserne, så du kan se alle punkterne1.
- Gå tilbage til regnearket og markér alle punkterne i kolonne
E. Højreklik og vælg "vis navn" (det skulle gerne fjerne navngivningen af punkterne i koordinatsystemet).
Vi vil nu farve de punkter, som svarer til et træningseksempel, hvor tilbuddet et blevet aktiveret for blåt og tilsvarende rødt, hvis tilbuddet ikke er blevet aktiveret. Husk på at denne information findes i kolonne D.
Markér det første punkt i celle
E2. Højreklik og vælg "Egenskaber". Vælg her fanen "Avanceret".I det felt, hvor der står "Rød", skriver du
If(D2="Nej",1,0).I det felt, hvor der står "Grøn", skriver du
0.I det felt, hvor der står "Blå", skriver du
If(D2="Ja",1,0).
Det kommer til at se sådan her ud (hvis du har GeoGebra på dansk bliver "If" lavet om til "Hvis"):
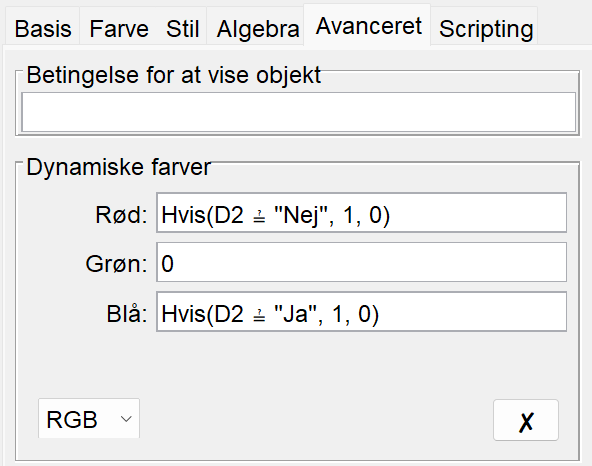
Forklaring: I GeoGebra repræsenteres farver ved hjælp af en rød/grøn/blå (RGB) farvemodel. Mængden af rød repræsenteres her som et tal mellem 0 og 1 og tilsvarende med grøn og blå. Når vi i feltet ved "Rød" skriver If(D2="Nej",1,0), så betyder det, at hvis værdien i celle D2 er "Nej" (kunden har ikke aktiveret tilbuddet), så skal mængden af rød være 1 og 0 ellers. Og tilsvarende for mængden af blå, hvis D2 har værdien "Ja".
Marker igen celle
E2og tag ved den lille kasse i nederste hjørne af celleE2og trække ned, så du igen får udfyldt kolonneEfor hele datasættet. Punkterne skulle nu gerne være farvet som ønsket.Indsæt nogle tekstfelter i tegneblokken (tryk på ikonet "Skyder" og vælg "Tekst"): Angiv, hvad der er ud af akserne, hvad de røde og blå punkter betyder, og at plottet er for kvinder.
Indlæg i dette koordinatsystem en ret linje, som (for de fleste punkter) vil kunne bruges til at adskille de blå punkter fra de røde? Notér ligningen for en sådan linje.
Lav et tilsvarende plot for mændene.
1 Tryk på ikonet "Flyt tegnefladen" og hold cursoren henover for eksempel \(y\)-aksen. Når cursoren ændrer sig til en dobbeltpil, kan du ved at holde venstre musetast nede ændre på enhederne på aksen.
Aktivitet 2 - Brug af app
I denne aktivitet skal vi træne en kunstig neuron på datasættet fra opgave 1. Det vil sige, at vi skal have bestemt vægtene \(w_0\), \(w_1\), \(w_2\) og \(w_3\), så vi kan bruge sigmoid-funktionen til at beregne outputværdien \(o\):
\[ o = \frac{1}{1+\mathrm{e}^{-(w_0+w_1 \cdot x_1+w_2 \cdot x_2+w_3 \cdot x_3)}} \]
Udfra outputværdien vil vi prædiktere targetværdien på denne måde:
\[ \textrm{Kunden aktiverer tilbuddet: } \begin{cases} \textrm{Ja} & \textrm{hvis } o \geq 0.5\\ \textrm{Nej} & \textrm{hvis } o < 0.5\\ \end{cases} \tag{1}\]
Vægtene bestemmer vi ved at træne en kunstig neuron (det vil sige, at vi minimerer tabsfunktionen ved hjælp af gradientnedstigning):
Vi husker nu på, at \(x_3\) angiver kundens køn. Det vil sige, at for kvinder er \(x_3=0\), og for mænd er \(x_3=1\). Det betyder, at vi kan lave en version af ligningen i (2) for kvinder og en anden for mænd:
\[ \begin{aligned} &\textrm{Kvinder:} \quad w_0+w_1 \cdot x_1+w_2 \cdot x_2 = 0 \\ &\textrm{Mænd:} \quad w_0+w_1 \cdot x_1+w_2 \cdot x_2+w_3 = 0 \end{aligned} \tag{3}\]
Den generelle ligning for en ret linje er på formen
\[ a \cdot x + b \cdot y + c = 0 \]
Vi kan derfor se, at de to ligninger i (3) begge er på formen for en ret linje. I næste opgave skal vi have tegnet de tilhørende rette linjer:
På baggrund af de to plots i opgave 5 skal vi have lavet en såkaldt confusion matrix og derefter beregnet en klassifikationsnøjagtighed.
Aktivitet 3 - Eksempel på slow learning
I aktivitet 2 i del 3 så vi, at man kan starte et sted på grafen for tabsfunktionen, som resulterer i "slow learning". Det vil sige, at det umiddelbart kan se ud som om, at man har fundet et minimum for tabsfunktionen, men i virkeligheden er man landet i et plateau, hvor værdien af tabsfunktionen kun ændrer sig langsomt.
Det skal vi se et konkret eksempel på nu.
Du har måske bemærket, at du har fået nogle andre værdier af vægtene her i opgave 7, end du gjorde i opgave 3. Lad os se lidt nærmere på det.