Aktiveringsfunktioner
Formål
I opbygningen af kunstige neurale netværk er aktiveringsfunktioner helt centrale. Hvis ikke man bruger aktiveringsfunktioner i et kunstigt neuralt netværk, vil man faktisk bare bygge en stor lineær funktion af inputværdierne. Og lineære funktioner kan man ikke prædiktere ret meget med!
Når man skal træne en perceptron, et simpelt neuralt netværk eller et helt generelt neuralt netværk, skal man kunne differentiere de aktiveringsfunktioner, som indgår. I dette forløb vil vi arbejde med nogle af de mange forskellige aktiveringsfunktioner, som anvendes i den virkelige verden. Vi skal se på grafer og værdimængde – og så skal vi mest af alt differentiere dem!
Introduktion
Når man træner en AI model, sker det som regel ved, at man forsøger at minimere de fejl, som modellen laver, når den anvendes på data, hvor man allerede kender svaret.
For at blive lidt mere konkret så minimerer man en såkaldt tabsfunktion \(E\) (\(E\) for error function), som har til formål at "måle", hvor god en AI model1 er. En tabsfunktion \(E\) har altid den egenskab, at \(E \geq 0\), og at en lille værdi af \(E\) svarer til en god model (der er et lille tab), mens en stor værdi af \(E\) svarer til en mindre god model. Derfor vælger man den model, som giver den mindste værdi af tabsfunktionen.
1 Med AI model tænker vi her på en perceptron, et simplet neuralt netværk, et generelt neuralt netværk eller en anden form for funktion, som kan bruges til at prædiktere et eller andet.
AI modellen trænes altså ved at finde minimum for tabsfunktionen. Det gøres ofte ved hjælp af gradientnedstigning – men den konkrete metode er ikke så vigtig lige nu. Det vigtige er her at forstå, at hvis man skal finde minimum for en funktion, så har man brug for at kunne differentiere.
Tabsfunktionen er en sammensat funktion. Den er sammensat af lineære funktioner, som vi kender rigtig godt fra tidligere, andengradspolynomier, og en særlig klasse af funktioner, som kaldes for aktiveringsfunktioner. Og det giver nok mening, at hvis man skal differentiere selve tabsfunktionen, så må man også kunne differentiere den anvendte aktiveringsfunktion \(f\).
Desuden viser det sig vigtigt, at det ikke må være alt for beregningsmæssigt tungt at beregne funktionsværdierne \(f(x)\) og \(f'(x)\). Det skal simpelthen gøres så mange gange – derfor dur det ikke, at det tager for lang tid. Det er derfor ønskværdigt, hvis en aktiveringsfunktions afledede funktion \(f'(x)\) kan beregnes forholdvis simpelt ved hjælp af \(f(x)\). Det betyder nemlig, at hvis vi allerede har udregnet \(f(x)\), så kræver det ikke ret meget også at udregne \(f'(x)\). Det kan illustreres med et eksempel:
Eksempel 1 Funktionen
\[ f(x)=\mathrm{e}^{kx} \]
har afledede funktion
\[ f'(x)=k \cdot \mathrm{e}^{kx} \]
Det vil sige, at vi kan udtrykke \(f'(x)\) ved hjælp af \(f(x)\) på denne måde:
\[ f'(x)= k \cdot f(x). \] Det betyder, at hvis man allerede har udregnet funktionsværdien \(f(x_0)\), så kan man meget nemt udregne tangenthældningen \(f'(x_0)\) i punktet \((x_0,f(x_0))\) ved at gange \(f(x_0)\) med \(k\).
Men ikke alle funktioner har denne egenskab, hvilket det næste eksempel illustrerer:
Eksempel 2 Grafen for funktionen
\[ f(x)=2x^3-3x^2-4x+5 \] ses i figur 1.
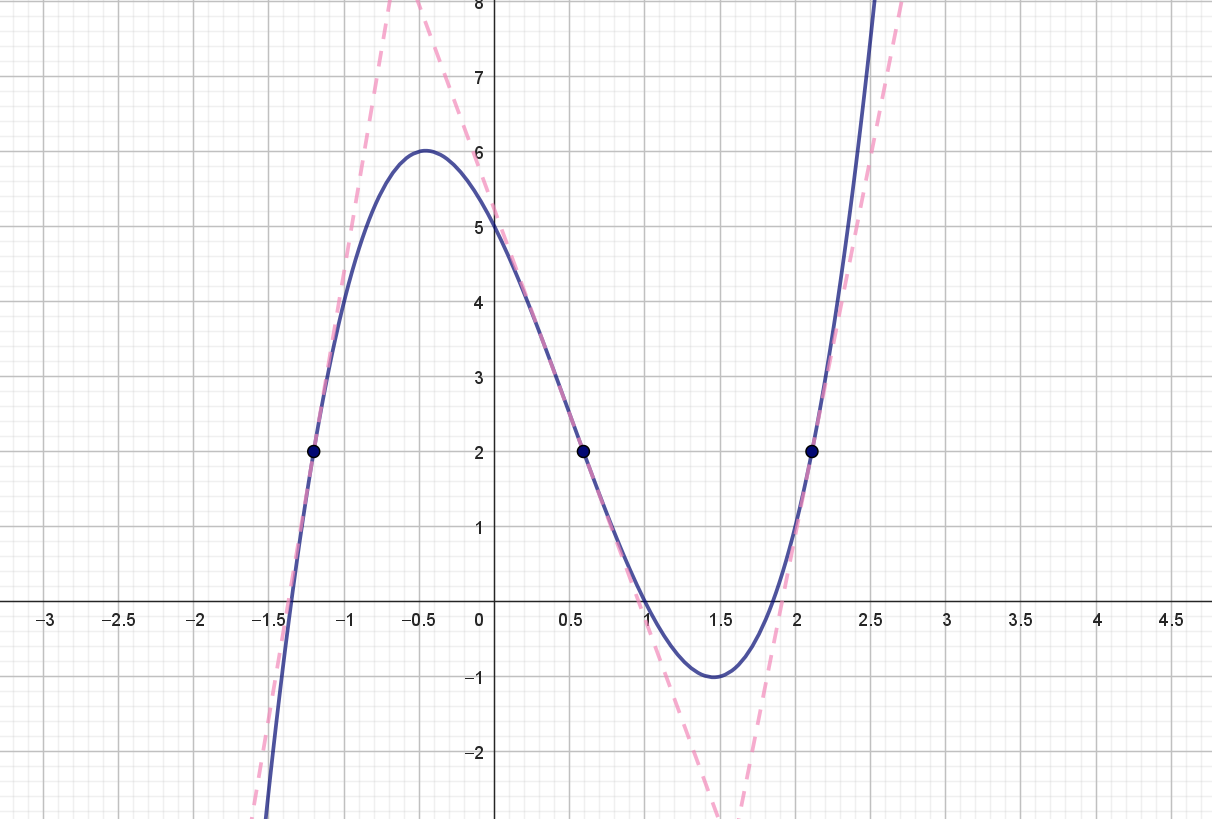
På grafen er der markeret tre punkter, hvor funktionsværdien er \(2\). I disse tre punkter er tangenten til grafen også indtegnet (som stiplede linjer). Her ses det tydeligt, at disse tangenters hældninger ikke er ens. Det betyder derfor, at \(f'(x)\) ikke kan beregnes simpelt alene ud fra funktionsværdien \(f(x)\).
Hvis du vil vide lidt mere om, hvad det der AI egentlig går ud på, så kan du se denne video:
I det nedenstående vil vi nu behandle en række af de mest anvendte aktiveringsfunktioner. Vi finder deres afledede funktioner, og vi vil se, hvordan de afledede funktioner alle kan udtrykkes ved hjælp af den oprindelig aktiveringsfunktion.
Sigmoid
Sigmoid-funktionen har forskrift
\[ f(x)=\frac{1}{1+\mathrm{e}^{-x}}, \tag{1}\]
som også kan skrives
\[ f(x)=\frac{\mathrm{e}^x}{1+\mathrm{e}^x}, \] hvilket ses med at gange med \(\mathrm{e}^x\) i både tæller og nævner i (1).
Grafen for Sigmoid-funktionen ses i figur 2.
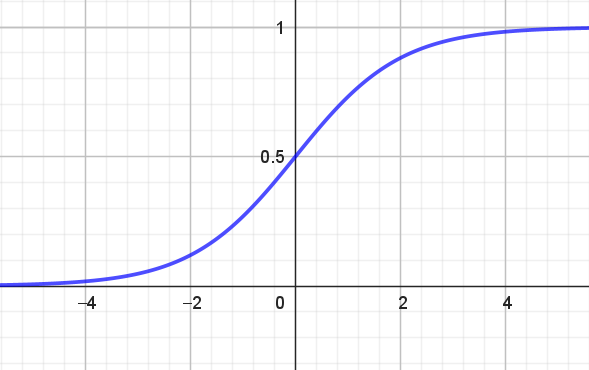
Det ser på figur 2 ud som om, at værdimængden for \(f\) er det åbne interval2 \((0,1)\). Det skrives
2 Bemærk, at det åbne interval \((0,1)\) også kan skrives \(]0,1[\).
\[ Vm(f)=(0,1). \]
Hvis du vil have et lidt bedre argument for det, kan du læse i boksen herunder.
Vi vil her argumentere for, at værdimængden for \(f\) er \((0,1)\). Vi vil starte med at se, at funktionsværdierne for \(f\) ligger mellem \(0\) og \(1\).
Da både tæller og nævner i (1) er positive, så må \(f(x)>0\). Og da
\[ 1<1+\mathrm{e}^{-x} \] så må
\[ \frac{1}{1+\mathrm{e}^{-x}}<\frac{1+\mathrm{e}^{-x}}{1+\mathrm{e}^{-x}}=1. \]
Det vil sige, at \[ 0 < f(x) < 1 \] og derfor må værdimængden for \(f\) være en del af intervallet \((0,1)\). Det kan skrives sådan her
\[ Vm(f) \subseteq (0,1). \] Vi vil nu vise, at vi kan komme lige så tæt på \(0\) og \(1\), som det skal være. Det vil med andre ord sige, at værdimængden for \(f\) "fylder" hele intervallet \((0,1)\) ud.
På figuren herunder ses grafen for \(\mathrm{e}^{-x}\).
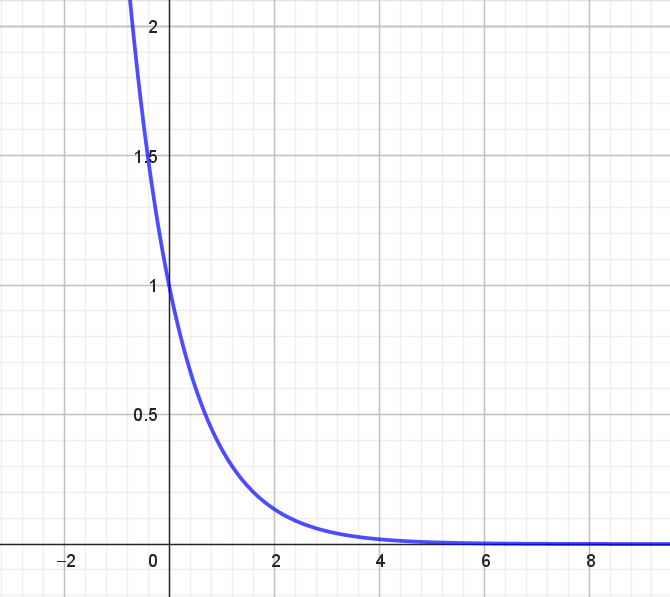
Da \(\mathrm{e}^{-x}\) er en aftagende eksponentialfunktion vil
\[ \mathrm{e}^{-x} \rightarrow 0 \quad \textrm{når} \quad x \rightarrow \infty \] og
\[ \mathrm{e}^{-x} \rightarrow \infty \quad \textrm{når} \quad x \rightarrow -\infty. \]
Det betyder, at \[ \frac{1}{1+\mathrm{e}^{-x}} \rightarrow 1 \quad \textrm{når} \quad x \rightarrow \infty \]
og
\[ \frac{1}{1+\mathrm{e}^{-x}} \rightarrow 0 \quad \textrm{når} \quad x \rightarrow -\infty. \]
Alt i alt har vi altså argumenteret for, at værdimængden for \(f\) er \((0,1)\).
De følgende opgaver går ud på at vise, at
\[ f'(x)= \frac{\mathrm{e}^{-x}}{(1+\mathrm{e}^{-x})^2} \] og at \(f'(x)\) kan udtrykkes ved hjælp af \(f(x)\) på denne måde
\[ f'(x)= f(x)\cdot (1-f(x)). \]
Softsign
Softsign-funktionen har forskrift
\[ f(x)=\frac{x}{1+|x|}. \] Husk på at \(|x|\) betyder den numeriske værdi af \(x\). Det vil sige
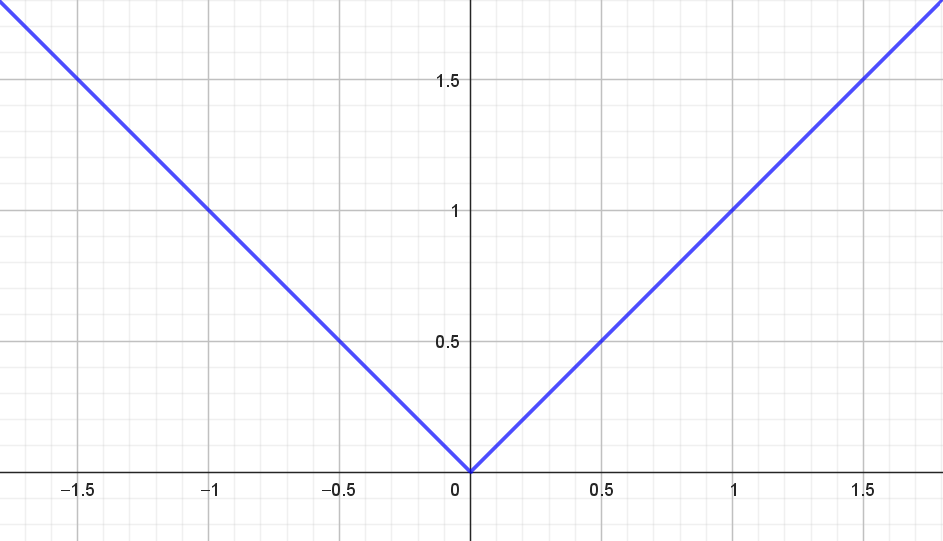
\[ |x| = \begin{cases} x & \textrm{hvis } x \geq 0 \\ -x & \textrm{hvis } x < 0 \\ \end{cases} \tag{2}\] Det betyder for eksempel at \(|7|=7\) og \(|-7|=7\). Grafen for \(|x|\) ses i figur 3.
Grafen for softsign-funktionen \(f\) ses i figur 4.
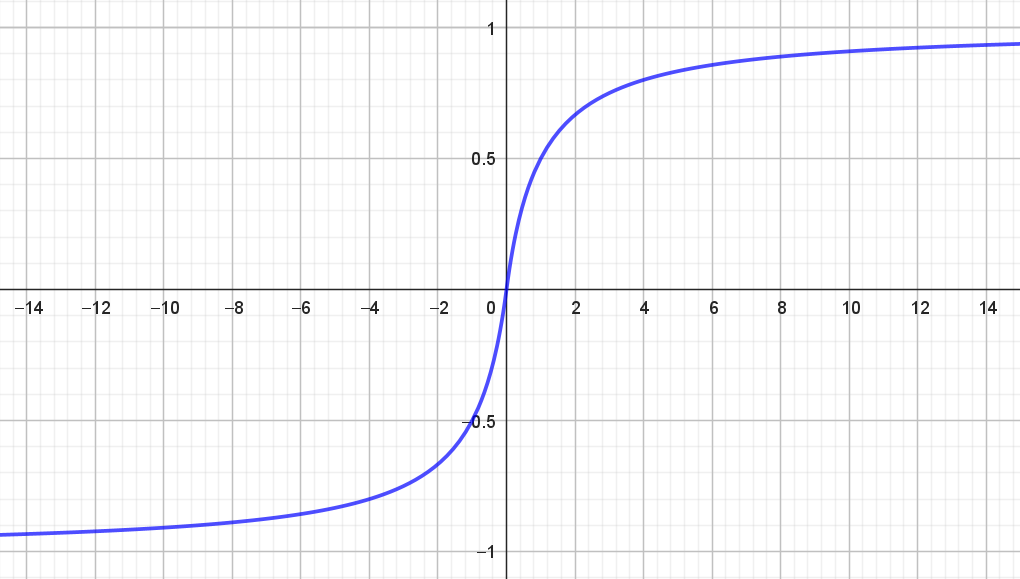
Da den numeriske værdi af \(x\) indgår i forskriften, kunne man få den tanke, at \(f\) måske hverken er kontinuert eller differentiabel i \(0\). For eksempel kan man i figur 3 se, at \(|x|\) ikke er differentiabel i \(0\).
Men bruger vi definitionen på \(|x|\), får vi
\[ f(x) = \begin{cases} \frac{x}{1+x} & \textrm{hvis } x \geq 0 \\ \\ \frac{x}{1-x} & \textrm{hvis } x < 0 \\ \end{cases} \tag{3}\]
Ud fra denne omskrivning kan man vise, at \(f\) rent faktisk er kontinuert i \(0\). Det kan du læse mere om i boksen herunder, hvis du har lyst.
På figur 4 ser det ud som om, at værdimængden for \(f\) er \((-1,1)\) (også det argumenterer vi for i boksen):
\[ Vm(f) = (-1,1). \]
Det vil sige, at hvis vi skal bruge softsign-funktionen som aktiveringsfunktion, så skal targetværdierne være \(\pm 1\).
I nedenstående opgaver skal vi vise, at
\[ f'(x)=\frac{1}{\left ( 1+ |x| \right )^2} \tag{4}\]
og at den afledte kan findes ved hjælp af funktionsværdien selv på denne måde
\[ f'(x)=(1-|f(x)|)^2. \tag{5}\]
Hyperbolsk tangens
Funktionen hyperbolsk tangens, \(\tanh\), har forskrift \[ \tanh(x) = \frac{\mathrm{e}^x-\mathrm{e}^{-x}}{\mathrm{e}^x+\mathrm{e}^{-x}} \]
Grafen for hyperbolsk tangens er vist i figur 5.
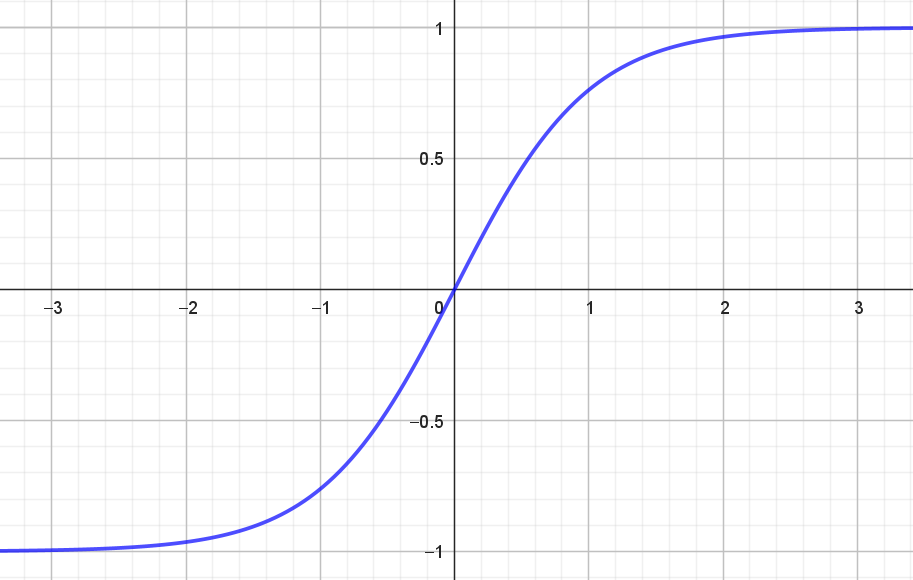
Ifølge figuren ser det ud til, at \(Vm(f)=(-1,1)\). Det argumenterer vi nærmere for i boksen herunder.
Vi starter med at vise, at
\[ -1 < \tanh(x) < 1. \] Da \[ - \mathrm{e}^x - \mathrm{e}^{-x} <\mathrm{e}^x - \mathrm{e}^{-x} < \mathrm{e}^x + \mathrm{e}^{-x} \] og \(\mathrm{e}^x + \mathrm{e}^{-x}>0\) vil
\[ -1 = \frac{- \mathrm{e}^x - \mathrm{e}^{-x}}{\mathrm{e}^x + \mathrm{e}^{-x}} < \frac{\mathrm{e}^x - \mathrm{e}^{-x}}{\mathrm{e}^x + \mathrm{e}^{-x}} < \frac{\mathrm{e}^x + \mathrm{e}^{-x}}{\mathrm{e}^x + \mathrm{e}^{-x}} = 1. \] Altså er \(-1 < \tanh(x)<1\). Vi mangler kun at argumentere for, at værdimængden for \(\tanh\) "fylder" hele intervallet \((-1,1)\) ud.
På figuren herunder ses grafen for den voksende eksponentialfunktion \(\mathrm{e}^x\) (blå) og for den aftagende eksponentialfunktion \(\mathrm{e}^{-x}\) (grøn).
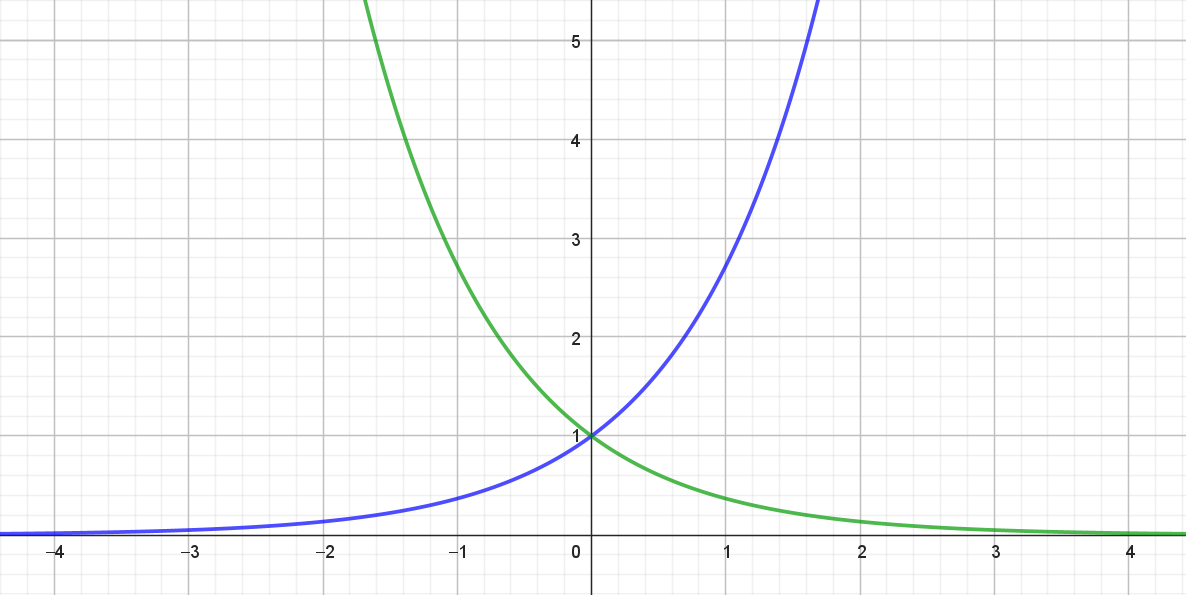
Her ses det, at for store positive værdier af \(x\) er \(\mathrm{e}^{-x} \approx 0\). Det vil sige, at for store positive værdier af \(x\) er
\[ \tanh(x)=\frac{\mathrm{e}^x-\mathrm{e}^{-x}}{\mathrm{e}^x+\mathrm{e}^{-x}} \approx \frac{\mathrm{e}^x-0}{\mathrm{e}^x+0}=\frac{\mathrm{e}^x}{\mathrm{e}^x}=1. \]
Omvendt gælder for store negative værdier af \(x\) er \(\mathrm{e}^x \approx 0\). Det vil sige, at for store negative værdier af \(x\) er
\[ \tanh(x)=\frac{\mathrm{e}^x-\mathrm{e}^{-x}}{\mathrm{e}^x+\mathrm{e}^{-x}} \approx \frac{0-\mathrm{e}^{-x}}{0+\mathrm{e}^{-x}}=\frac{-\mathrm{e}^{-x}}{\mathrm{e}^{-x}}=-1. \] Det betyder, at \[ \tanh(x) \rightarrow 1 \quad \textrm{når} \quad x \rightarrow \infty \] og
\[ \tanh(x) \rightarrow -1 \quad \textrm{når} \quad x \rightarrow - \infty \] hvilket stemmer fint overens med figur 5. Man siger for øvrigt, at linjerne med ligning \(y=-1\) og \(y=1\) er vandrette asymptoter.
Altså har vi vist, at \[ Vm(\tanh)=(-1,1). \]
I nedenstående opgave skal vi vise, at \(\tanh\) differentieret er
\[ \tanh'(x)=1-\left ( \tanh(x) \right )^2. \]
For at bevise det er det nemmeste at bruge kvotientreglen for differentiation. Måske har du hørt om den – måske har du ikke. Men her kommer den:
Kvotientreglen for differentiation
\[ \left ( \frac{f}{g}\right)'(x) = \frac{f'(x) \cdot g(x)-f(x) \cdot g'(x)}{(g(x))^2}, \quad g(x) \neq 0 \]
ReLU
Aktiveringsfunktionen ReLU som står for Reflected Linear Unit har forskrift
\[ f(x) = \begin{cases} x & \textrm{hvis } x > 0 \\ 0 & \textrm{hvis } x \leq 0 \\ \end{cases} \] og grafen for ReLU-funktionen ses i figur 6.
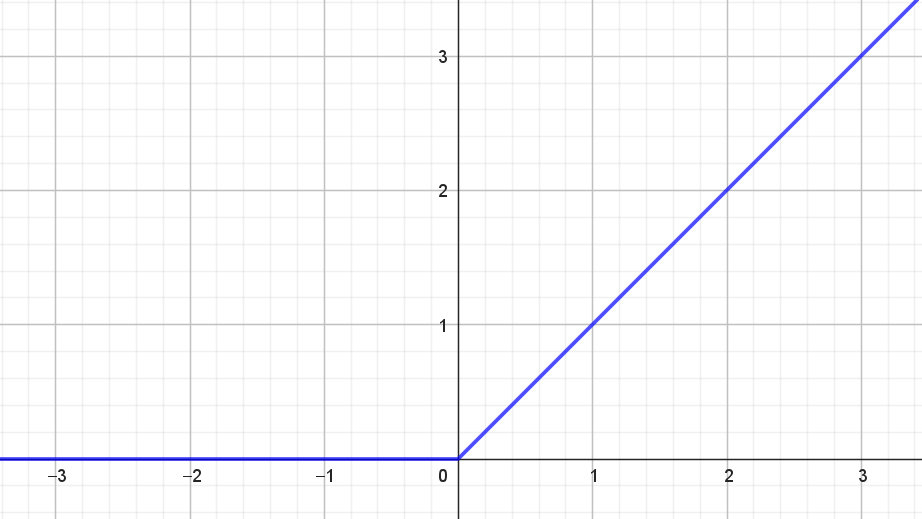
Værdimængden for ReLU-funktionen er \([0, \infty)\).
Det er ret tydeligt, at ReLU-funktionen ikke er differentiabel i \(0\). Men hvis vi definerer, at \(f'(0)\) skal være \(0\) så ses det nemt, at
\[ f'(x) = \begin{cases} 1 & \textrm{hvis } x > 0 \\ 0 & \textrm{hvis } x \leq 0 \\ \end{cases}. \]
ReLU-funktionen adskiller sig fra de andre aktiveringsfunktioner ved, at værdimængden er ubegrænset. Hvis man ønsker at bruge aktiveringsfunktionen til at modellere en sandsynlighed, som beskrevet tidligere, så dur det selvfølgelig ikke. Men i praksis viser ReLU-funktionen sig at være utrolig anvendelig som aktiveringsfunktion i de skjulte lag i kunstige neurale netværk. For det første kan nogle af de andre aktiveringsfunktioner resultere i det, vi i afsnittet om valg af tabsfunktion i noten om kunstige neurale netværk, kalder for slow learning. Det betyder kort sagt, at det går for langsomt med at finde minimum for tabsfunktionen. Dét problem har ReLU-funktionen ikke. For det andet er det meget hurtigt og nemt at udregne både ReLU-funktionen selv og også dens afledede. Det er for eksempel til sammenligning beregningsmæssigt tungere at udregne sigmoid-funktionen og dennes afledede. Hvis man har et netværk med millioner af neuroner, så er denne beregningsmæssige forskel ikke uvæsentlig.
For yderligere læsning henviser vi til referencerne i afsnittet videre læsning.
Overblik
I tabellen herunder finder du et overblik over de forskellige aktiveringsfunktioner, som vi har behandlet ovenfor.
| Navn | \(f(x)\) | Graf | \(Vm(f)\) | \(f'(x)\) | |
|---|---|---|---|---|---|
| Sigmoid | \(\frac{1}{1+\mathrm{e}^{-x}}\) |  |
\((0,1)\) | \(f(x)\cdot(1-f(x))\) | |
| Softsign | \(\frac{x}{1+|x|}\) |  |
\((-1,1)\) | \((1-|f(x)|)^2\) | |
| Hyperbolsk tangens | \(\frac{\mathrm{e}^x-\mathrm{e}^{-x}}{\mathrm{e}^x+\mathrm{e}^{-x}}\) |  |
\((-1,1)\) | \(1-\left ( \tanh(x) \right )^2\) | |
| ReLU | \(\begin{cases} x & \textrm{hvis } x > 0 \\ 0 & \textrm{hvis } x \leq 0 \\ \end{cases}\) |  |
\([0,\infty)\) | \(\begin{cases} 1 & \textrm{hvis } x > 0 \\ 0 & \textrm{hvis } x \leq 0 \\ \end{cases}\) |